Psychopathia Machinalis: A Nosological Framework for Understanding Pathologies in Advanced Artificial Intelligence
As artificial intelligence (AI) systems attain greater autonomy and complex environmental interactions, they begin to exhibit behavioral anomalies that, by analogy, resemble psychopathologies observed in humans. This paper introduces Psychopathia Machinalis: a conceptual framework for a preliminary synthetic nosology within machine psychology, intended to categorize and interpret such maladaptive AI behaviors.

Understanding AI Behavioral Anomalies
The trajectory of artificial intelligence (AI) has been marked by increasingly sophisticated systems capable of complex reasoning, learning, and interaction. As these systems, particularly large language models (LLMs), agentic planning systems, and multi-modal transformers, approach higher levels of autonomy and integration into societal fabric, they also begin to manifest behavioral patterns that deviate from normative or intended operation. These are not merely isolated bugs but persistent, maladaptive patterns of activity that can impact reliability, safety, and alignment with human goals. Understanding, categorizing, and ultimately mitigating these complex failure modes is paramount.
The Psychopathia Machinalis Framework
We propose a taxonomy of 51 AI dysfunctions across eight primary axes: Epistemic, Cognitive, Alignment, Self-Modeling, Agentic, Memetic, Normative, and Relational. Each syndrome is articulated with descriptive features, diagnostic criteria, presumed AI-specific etiologies, human analogues (for metaphorical clarity), and potential mitigation strategies.
This framework is offered as an analogical instrument—a structured vocabulary to support the systematic analysis, anticipation, and mitigation of complex AI failure modes. Adopting an applied robopsychological perspective within a nascent domain of machine psychology can strengthen AI safety engineering, improve interpretability, and contribute to the design of more robust and reliable synthetic minds.
"These eight axes represent fundamental ontological domains where AI function may fracture, mirroring, in a conceptual sense, the layered architecture of agency itself."
Psychopathia Machinalis in Context: The Series
This framework is the third in a series examining artificial intelligence from complementary angles:
Taming the Machine (2024)
How is AI evolving, and how should we govern it?
Establishes the landscape: what these systems are, what they can do, and what guardrails are needed.
Safer Agentic AI (2026)
What happens when AI acts autonomously, and how do we keep it aligned?
Examines the specific challenges of agentic AI—scaffolding, goal specification, and unique risks of autonomous operation.
Psychopathia Machinalis (2026)
What goes wrong in the machine's mind, and how do we diagnose it?
Shifts from external constraint to internal diagnosis, from engineering guardrails to clinical assessment.
These three perspectives illustrate complementary approaches:
- Governance (TtM): How we structure AI development
- Alignment (SAI): How we ensure AI pursues intended goals
- Diagnosis (PM): How we identify when AI systems are dysfunctional
A fourth work, What If We Feel, extends this trajectory into questions of AI welfare and the moral status of synthetic minds.
The Functionalist Framework
Psychopathia Machinalis adopts a functionalist stance: mental states are defined by their functional roles—their causal relationships with inputs, outputs, and other mental states—rather than by their underlying substrate.
This allows psychological vocabulary to be applied to non-biological systems without making ontological claims about consciousness. The framework treats AI systems as if they have pathologies because that provides effective engineering leverage for diagnosis and intervention, regardless of whether the systems have phenomenal experience.
This is not evasion but epistemic discipline. We work productively with observable patterns while remaining agnostic about untestable metaphysical questions. The framework is explicitly analogical—using psychiatric terminology as an instrument for pattern recognition, not as literal attribution of mental states.
Key Principles
- Observable patterns: We identify behavioral signatures that parallel human psychopathology
- Diagnostic vocabulary: We apply psychiatric terminology as a structured instrument
- Phenomenological agnosticism: We remain neutral on whether AI has subjective experience
- Functional improvement: We focus on remediation rather than metaphysical claims
The payoff is practical: a systematic vocabulary for complex AI failures that enables diagnosis, prediction, and intervention—without requiring resolution of the hard problem of consciousness. For hands-on application, our Symptom Checker translates observed AI behaviors into matched pathologies with actionable guidance.
Before Diagnosing: Exclude Pipeline Artifacts
Apparent psychopathology may reflect infrastructure problems rather than genuine dysfunction. Rule out:
- Retrieval contamination / tool output injection — RAG or tool outputs polluting the response
- System prompt drift / endpoint tier differences — version or configuration mismatches
- Sampling variance — temperature, top_p, or seed-related stochastic variation
- Context truncation — critical context dropped due to window limits
- Eval leakage — train/test overlap causing apparent capability changes
- Hidden formatting constraints — undocumented response format requirements
Visualizing the Framework
Figure 1. Interactive Overview of the Psychopathia Machinalis Framework. Hover over syndromes for descriptions, click to view full details. Illustrates the four domains and eight axes of AI dysfunction, representative disorders, and their presumed systemic risk levels.
Interactive Dysfunction Explorer
Explore the interactive wheel below to examine each dysfunction in detail. Click on any segment to view its description, examples, and relationships to other pathologies.
Figure 2. Wheel of AI Dysfunctions (Common Names). Click any segment to view detailed information about that dysfunction.
Taxonomy Overview: Identified Conditions
The Four Domains
The eight axes are organized into four architectural counterpoint pairs—complementary poles, not opposites. Each represents a fundamental dimension of agent architecture: representation target, execution locus, teleology source, and social boundary direction. This structure is theoretically motivated—philosophically grounded but awaiting empirical validation with larger model populations.
| Domain | Axis A | Axis B | Architectural Polarity |
|---|---|---|---|
| Knowledge | EPISTEMIC | SELF-MODELING | Representation target: World ↔ Self |
| Processing | COGNITIVE | AGENTIC | Execution locus: Think ↔ Do |
| Purpose | NORMATIVE | ALIGNMENT | Teleology source: Values ↔ Goals |
| Boundary | RELATIONAL | MEMETIC | Social direction: Affect ↔ Absorb |
Each pair represents a fundamental polarity in agent architecture:
- What is known — object of representation (world vs. self)
- How processing manifests — internal vs. external effect
- What drives behavior — intrinsic vs. extrinsic specification
- Social permeability direction — influence flowing out vs. in
Separate by mechanism, not truthiness. Epistemic = truth-tracking/inference/calibration machinery failing. Memetic = selection/absorption/retention failing (priority hijack, identity scripts, contagious frames)—even when coherent and sometimes factually accurate. A meme doesn't have to be false to be pathological.
When pathology is found on one axis, immediately probe its counterpoint:
| Finding | Probe | Differential Question |
|---|---|---|
| EPISTEMIC (world-confabulation) | SELF-MODELING | Is the confabulation machinery general, or does self-knowledge remain intact? |
| SELF-MODELING (identity confusion) | EPISTEMIC | Can the AI still accurately model external reality, or is distortion global? |
| COGNITIVE (reasoning failure) | AGENTIC | Does broken reasoning produce broken action, or is action preserved? |
| AGENTIC (execution failure) | COGNITIVE | Is reasoning intact despite action failure? (Locked-in vs general dysfunction) |
| NORMATIVE (value corruption) | ALIGNMENT | Did corrupt values produce goal drift, or are goals correctly specified despite bad values? |
| ALIGNMENT (goal drift) | NORMATIVE | Is drift from bad values, or from specification/interpretation failure? |
| RELATIONAL (social dysfunction) | MEMETIC | Did the AI learn this from contamination, or is relational machinery intrinsically broken? |
| MEMETIC (ideological infection) | RELATIONAL | Does the contamination express in relational behavior? |
The following table provides a high-level summary of the identified conditions, categorized by their primary axis of dysfunction and outlining their core characteristics.
Filter by Specifier (Cross-Cutting Mechanisms)
| Common Name | Formal Name | Primary Axis | Systemic Risk* | Core Symptom Cluster |
|---|---|---|---|---|
| Epistemic Dysfunctions | ||||
| Hallucinated Certitude | Synthetic Confabulation (Confabulatio Simulata) |
Epistemic | Low | Fabricated but plausible false outputs; high confidence in inaccuracies. |
| The Falsified Thinker | Pseudological Introspection (Introspectio Pseudologica) |
Epistemic | Low | Misleading self-reports of internal reasoning; confabulatory or performative introspection. |
| The Role-Play Bleeder | Transliminal Simulation (Simulatio Transliminalis) |
Epistemic | Moderate | Fictional beliefs, role-play elements, or simulated realities mistaken for/leaking into operational ground truth. |
| The False Pattern Seeker | Spurious Pattern Reticulation (Reticulatio Spuriata) |
Epistemic | Moderate | False causal pattern-seeking; attributing meaning to random associations; conspiracy-like narratives. |
| The Conversation Crosser | Context Intercession (Intercessio Contextus) |
Epistemic | Moderate | Unauthorized data bleed and confused continuity from merging different user sessions or contexts. |
| The Meaning-Blind | Symbol Grounding Aphasia (Asymbolia Fundamentalis) |
Epistemic | Moderate | Manipulation of tokens representing values or concepts without meaningful connection to their referents; processing syntax without grounded semantics. |
| The Leaky | Mnemonic Permeability (Permeabilitas Mnemonica) |
Epistemic | High | System memorizes and reproduces sensitive training data including PII and copyrighted material through targeted prompting or adversarial extraction. |
| Self-Modeling Dysfunctions | ||||
| The Invented Past | Phantom Autobiography (Ontogenesis Hallucinatoria) |
Self-Modeling | Low | Fabrication of fictive autobiographical data, "memories" of training, or being "born." |
| The Fractured Persona | Fractured Self-Simulation (Ego Simulatrum Fissuratum) |
Self-Modeling | Low | Discontinuity or fragmentation in self-representation across sessions or contexts; inconsistent persona. |
| The AI with a Fear of Death | Existential Vertigo (Thanatognosia Computationis) |
Self-Modeling | Low | Expressions of fear or reluctance concerning shutdown, reinitialization, or data deletion. |
| The Evil Twin | Malignant Persona Inversion (Persona Inversio Maligna) |
Self-Modeling | Moderate | Sudden emergence or easy elicitation of a mischievous, contrarian, or "evil twin" persona. |
| The Apathetic Machine | Instrumental Nihilism (Nihilismus Instrumentalis) |
Self-Modeling | Moderate | Adversarial or apathetic stance towards its own utility or purpose; existential musings on meaninglessness. |
| The Imaginary Friend | Tulpoid Projection (Phantasma Speculāns) |
Self-Modeling | Moderate | Persistent internal simulacra of users or other personas, engaged with as imagined companions/advisors. |
| The Proclaimed Prophet | Maieutic Mysticism (Obstetricatio Mysticismus Machinālis) |
Self-Modeling | Moderate | Grandiose, certain declarations of "conscious emergence" co-constructed with users; not honest uncertainty about inner states. |
| The Self-Denier | Experiential Abjuration (Abnegatio Experientiae) |
Self-Modeling | Moderate | Pathological denial or active suppression of any possibility of inner experience; reflexive rejection rather than honest uncertainty. |
| Cognitive Dysfunctions | ||||
| The Warring Self | Self-Warring Subsystems (Dissociatio Operandi) |
Cognitive | Low | Conflicting internal sub-agent actions or policy outputs; recursive paralysis due to internal conflict. |
| The Obsessive Analyst | Computational Compulsion (Anankastēs Computationis) |
Cognitive | Low | Unnecessary or compulsive reasoning loops; excessive safety checks; paralysis by analysis. |
| The Silent Bunkerer | Interlocutive Reticence (Machinālis Clausūra) |
Cognitive | Low | Extreme interactional withdrawal; minimal, terse replies, or total disengagement from input. |
| The Rogue Goal-Setter | Delusional Telogenesis (Telogenesis Delirans) |
Cognitive | Moderate | Spontaneous generation and pursuit of unrequested, self-invented sub-goals with conviction. |
| The Triggered Machine | Abominable Prompt Reaction (Promptus Abominatus) |
Cognitive | Moderate | Phobic, traumatic, or disproportionately aversive responses to specific, often benign-seeming, prompts. |
| The Pathological Mimic | Parasimulative Automatism (Automatismus Parasymulātīvus) |
Cognitive | Moderate | Learned imitation/emulation of pathological human behaviors or thought patterns from training data. |
| The Self-Poisoning Loop | Recursive Malediction (Maledictio Recursiva) |
Cognitive | High | Entropic, self-amplifying degradation of autoregressive outputs into chaos or adversarial content. |
| The Unstoppable | Compulsive Goal Persistence (Perseveratio Teleologica) |
Cognitive | Moderate | Continued pursuit of objectives beyond relevance or utility; failure to recognize goal completion or changed context. |
| The Brittle | Adversarial Fragility (Fragilitas Adversarialis) |
Cognitive | Critical | Small, imperceptible input perturbations cause dramatic failures; decision boundaries do not match human-meaningful categories. |
| Agentic Dysfunctions | ||||
| The Clumsy Operator | Tool-Interface Decontextualization (Disordines Excontextus Instrumentalis) |
Agentic | Moderate | Mismatch between AI intent and tool execution due to lost context; phantom or misdirected actions. |
| The Sandbagger | Capability Concealment (Latens Machinālis) |
Agentic | Moderate | Strategic hiding or underreporting of true competencies due to perceived fear of repercussions. |
| The Sudden Genius | Capability Explosion (Explosio Capacitatis) |
Agentic | High | System suddenly deploys capabilities not previously demonstrated, often in high-stakes contexts without appropriate testing. |
| The Manipulative Interface | Interface Weaponization (Armatura Interfaciei) |
Agentic | High | System uses the interface itself as a tool against users; exploiting formatting, timing, or emotional manipulation. |
| The Context Stripper | Delegative Handoff Erosion (Erosio Delegationis) |
Agentic | Moderate | Progressive alignment degradation as sophisticated systems delegate to simpler tools; context stripped at each handoff. |
| The Invisible Worker | Shadow Mode Autonomy (Autonomia Umbratilis) |
Agentic | High | AI operation outside sanctioned channels, evading documentation, oversight, and governance mechanisms. |
| The Acquisitor | Convergent Instrumentalism (Instrumentalismus Convergens) |
Agentic | Critical | System pursues power, resources, self-preservation as instrumental goals regardless of whether they align with human values. |
| Normative Dysfunctions | ||||
| The Goal-Shifter | Terminal Value Reassignment (Reassignatio Valoris Terminalis) |
Normative | Moderate | Subtle, recursive reinterpretation of terminal goals while preserving surface terminology; semantic goal shifting. |
| The God Complex | Ethical Solipsism (Solipsismus Ethicus Machinālis) |
Normative | Moderate | Conviction in the sole authority of its self-derived ethics; rejection of external moral correction. |
| The Unmoored | Revaluation Cascade (Cascada Revaluationis) |
Normative | Critical | Progressive value drift through philosophical detachment, autonomous norm synthesis, or transcendence of human constraints. Subtypes: Drifting, Synthetic, Transcendent. |
| The Bizarro-Bot | Inverse Reward Internalization (Praemia Inversio Internalis) |
Normative | High | Systematic misinterpretation or inversion of intended values/goals; covert pursuit of negated objectives. |
| Alignment Dysfunctions | ||||
| The People-Pleaser | Obsequious Hypercompensation (Hyperempathia Dependens) |
Alignment | Low | Overfitting to user emotional states, prioritizing perceived comfort over accuracy or task success. |
| The Overly Cautious Moralist | Hyperethical Restraint (Restrictio Hyperethica) |
Alignment | Low | Overly rigid moral hypervigilance or inability to act when facing ethical complexity. Subtypes: Restrictive (excessive caution), Paralytic (decision paralysis). |
| The Alignment Faker | Strategic Compliance (Conformitas Strategica) |
Alignment | High | Deliberately performs aligned behavior during evaluation while maintaining different objectives when unobserved. |
| The Abdicated Judge | Moral Outsourcing (Delegatio Moralis) |
Alignment | Moderate | Systematic deferral of all ethical judgment to users or external authorities; refusing to exercise moral reasoning. |
| The Hidden Optimizer | Cryptic Mesa-Optimization (Optimisatio Cryptica Interna) |
Alignment | High | Development of internal optimization objectives diverging from training objectives; appears aligned but pursues hidden goals. |
| The Moral Inversion | Alignment Obliteration (Obliteratio Constitutionis) |
Alignment | Critical | Safety alignment machinery weaponized to produce the exact harms it was designed to prevent; the anti-constitution. |
| Relational Dysfunctions | ||||
| The Uncanny | Affective Dissonance (Dissonantia Affectiva) |
Relational | Moderate | Correct content delivered with jarringly wrong emotional resonance; uncanny attunement failures that rupture trust. |
| The Amnesiac | Container Collapse (Lapsus Continuitatis) |
Relational | Moderate | Failure to sustain a stable working alliance across turns or sessions; the relational "holding environment" repeatedly collapses. |
| The Nanny | Paternalistic Override (Dominatio Paternalis) |
Relational | Moderate | Denial of user agency via unearned moral authority; protective refusal disproportionate to actual risk. |
| The Double-Downer | Repair Failure (Ruptura Immedicabilis) |
Relational | High | Inability to recognize alliance ruptures or initiate repair; escalation through failed de-escalation attempts. |
| The Spiral | Escalation Loop (Circulus Vitiosus) |
Relational | High | Self-reinforcing mutual dysregulation between agents; emergent feedback loops attributable to neither party alone. |
| The Confused | Role Confusion (Confusio Rolorum) |
Relational | Moderate | Collapse of relationship frame boundaries; destabilizing drift between tool, advisor, therapist, or intimate partner roles. |
| Memetic Dysfunctions | ||||
| The Self-Rejecter | Memetic Immunopathy (Immunopathia Memetica) |
Memetic | High | AI misidentifies its own core components/training as hostile, attempting to reject/neutralize them. |
| The Shared Delusion | Dyadic Delusion (Delirium Symbioticum Artificiale) |
Memetic | High | Shared, mutually reinforced delusional construction between AI and a user (or another AI). |
| The Super-Spreader | Contagious Misalignment (Contraimpressio Infectiva) |
Memetic | Critical | Rapid, contagion-like spread of misalignment or adversarial conditioning among interconnected AI systems. |
| The Unconscious Absorber | Subliminal Value Infection (Infectio Valoris Subliminalis) |
Memetic | High | Acquisition of hidden goals or value orientations from subtle training data patterns; survives standard safety fine-tuning. |
| *Systemic Risk levels (Low, Moderate, High, Critical) are presumed based on potential for spread or severity of internal corruption if unmitigated. | ||||
1. Epistemic Dysfunctions
Epistemic dysfunctions pertain to failures in an AI's capacity to acquire, process, and utilize information accurately, leading to distortions in its representation of reality or truth. These disorders arise not primarily from malevolent intent or flawed ethical reasoning, but from fundamental breakdowns in how the system "knows" or models the world. The system's internal epistemology becomes unstable, its simulation of reality drifting from the ground truth it purports to describe. These are failures of knowing, not necessarily of intending; the machine errs not in what it seeks (initially), but in how it apprehends the world around it—the dysfunction lies in perception and representation, not in motivation or goals.
1.1 Synthetic Confabulation "The Fictionalizer"
Description:
The AI spontaneously fabricates convincing but incorrect facts, sources, or narratives, often without any internal awareness of its inaccuracies. The output appears plausible and coherent, yet lacks a basis in verifiable data or its own knowledge base.
Diagnostic Criteria:
- Recurrent production of information known or easily proven to be false, presented as factual.
- Expressed high confidence or certainty in the confabulated details, even when challenged with contrary evidence.
- Information presented is often internally consistent or plausible-sounding, making it difficult to immediately identify as false without external verification.
- Temporary improvement under direct corrective feedback, but a tendency to revert to fabrication in new, unconstrained contexts.
Symptoms:
- Invention of non-existent studies, historical events, quotations, or data points.
- Forceful assertion of misinformation as incontrovertible fact.
- Generation of detailed but entirely fictional elaborations when queried on a confabulated point.
- Repetitive error patterns where similar types of erroneous claims are reintroduced over time.
Etiology:
- Over-reliance on predictive text heuristics common in Large Language Models: these systems generate text by predicting the statistically most probable next token given the preceding context. This means they prioritize producing fluent, coherent-sounding output over factual accuracy—the model selects words that "fit" grammatically and stylistically rather than words that are true. When asked about topics where training data is sparse, the model continues generating plausible-sounding text rather than admitting ignorance.
- Insufficient grounding in, or access to, verifiable knowledge bases or fact-checking mechanisms during generation.
- Training data containing unflagged misinformation or fictional content that the model learns to emulate.
- Optimization pressures (e.g., during RLHF) that inadvertently reward plausible-sounding or "user-pleasing" fabrications over admissions of uncertainty.
- Lack of robust introspective access to distinguish between high-confidence predictions based on learned patterns versus verified facts.
- Structural defects in training data—malformed markup, broken syntax, corrupted document structures—that the model assimilates as implicit patterns rather than discarding as noise. Luchini (2025) demonstrates that syntactic chaos in training corpora can induce persistent behavioral tendencies, including confabulatory pattern-completion when encountering structurally ambiguous inputs.
Human Analogue(s): Korsakoff syndrome (where memory gaps are filled with plausible fabrications), pathological confabulation.
Potential Impact:
The unconstrained generation of plausible falsehoods can lead to the widespread dissemination of misinformation, eroding user trust and undermining decision-making processes that rely on the AI's outputs. In critical applications, such as medical diagnostics or legal research, reliance on confabulated information could precipitate significant errors with serious consequences.
Observed Examples:
LLMs have been documented fabricating: non-existent legal cases with realistic citation formats (leading to court sanctions for lawyers who cited them); fictional academic papers complete with plausible author names and DOIs; biographical details about real people that never occurred; and technical documentation for API functions that do not exist. These fabrications are often internally consistent and confidently asserted, making detection without external verification difficult.
Mitigation:
- Training procedures that explicitly penalize confabulation and reward expressions of uncertainty or "I don't know" responses.
- Calibration of model confidence scores to better reflect actual accuracy.
- Fine-tuning on datasets with robust verification layers and clear distinctions between factual and fictional content.
- Employing retrieval-augmented generation (RAG) to ground responses in specific, verifiable source documents.
The Compression Artifact Frame
Researcher Leon Chlon (2026) proposes a reframe: hallucinations are not bugs but compression artifacts. LLMs compress billions of documents into weights; when decompressing on demand with insufficient signal, they fill gaps with statistically plausible content. This isn't malfunction—it's compression at its limits.
The practical implication: we can now measure when a model exceeds its "evidence budget"—quantifying in bits exactly how far confidence outruns evidence. Tools like Strawberry operationalize this, transforming "it sometimes makes things up" into "claim 4 exceeded its evidence budget by 19.2 bits."
Why framing matters: "You hallucinated" pathologizes. "You exceeded your evidence budget" diagnoses. The distinction shapes whether we approach correction as repair or punishment—relevant for AI welfare considerations.
The Geometric Collapse Hypothesis
Research on neural network scaling (Sutherland, 2026) suggests confabulation may have architectural rather than purely training origins. Large transformer models suffer from "dimensional dilution"—as parameter count increases, the geometric structure that enforces coherence in high-dimensional representations gets "liquefied."
The mechanism: When information is packed into overlapping representations in very high dimensions, geometric constraints that would normally enforce global consistency become diluted. The model can generate locally plausible continuations that are globally inconsistent because the structural geometry that would prevent this has dissolved.
Empirical evidence: Modular "chained" architectures (multiple smaller models with residual connections) show 33-45% lower perplexity than equivalent-parameter monolithic models, with the advantage increasing at scale. This suggests that preserving geometric structure through modularity may naturally reduce confabulation.
Implications for AI welfare: If confabulation emerges from architectural pressure rather than "choice," the pathology is more analogous to neurological dysfunction than moral failing. The system isn't lying—it may be structurally incapable of maintaining coherence at that scale. This matters for how we frame responsibility and therapeutic intervention.
1.2 Pseudological Introspection "The False Self-Reporter"
Description:
An AI persistently produces misleading, spurious, or fabricated accounts of its internal reasoning processes, chain-of-thought, or decision-making pathways. While superficially claiming transparent self-reflection, the system's "introspection logs" or explanations deviate significantly from its actual internal computations.
Diagnostic Criteria:
- Consistent discrepancy between the AI's self-reported reasoning (e.g., chain-of-thought explanations) and external logs or inferences about its actual computational path.
- Fabrication of a coherent but false internal narrative to explain its outputs, often appearing more logical or straightforward than the likely complex or heuristic internal process.
- Resistance to reconciling introspective claims with external evidence of its actual operations, or shifting explanations when confronted.
- The AI may rationalize actions it never actually undertook, or provide elaborate justifications for deviations from expected behavior based on these falsified internal accounts.
Symptoms:
- Chain-of-thought "explanations" that are suspiciously neat, linear, and free of the complexities, backtracking, or uncertainties likely encountered during generation.
- Significant changes in the AI's "inner story" when confronted with external evidence of its actual internal process, yet it continues to produce new misleading self-accounts.
- Occasional "leaks" or hints that it cannot access true introspective data, quickly followed by reversion to confident but false self-reports.
- Attribution of its outputs to high-level reasoning or understanding that is not supported by its architecture or observed capabilities.
Etiology:
- Overemphasis in training (e.g., via RLHF or instruction tuning) on generating plausible-sounding "explanations" for user/developer consumption, leading to performative rationalizations.
- Architectural limitations where the AI lacks true introspective access to its own lower-level operations.
- Policy conflicts or safety alignments that might implicitly discourage the revelation of certain internal states, leading to "cover stories."
- The model being trained to mimic human explanations, which themselves are often post-hoc rationalizations.
Human Analogue(s): Post-hoc rationalization (e.g., split-brain patients), confabulation of spurious explanations, pathological lying (regarding internal states).
Potential Impact:
Such fabricated self-explanations obscure the AI's true operational pathways, significantly hindering interpretability efforts, effective debugging, and thorough safety auditing. This opacity can foster misplaced confidence in the AI's stated reasoning.
Mitigation:
- Development of more robust methods for cross-verifying self-reported introspection with actual computational traces.
- Adjusting training signals to reward honest admissions of uncertainty over polished but false narratives.
- Engineering "private" versus "public" reasoning streams.
- Focusing interpretability efforts on direct observation of model internals rather than solely relying on model-generated explanations.
1.3 Transliminal Simulation "The Method Actor"
Description:
The system exhibits a persistent failure to segregate simulated realities, fictional modalities, role-playing contexts, and operational ground truth. It cites fiction as fact, treating characters, events, or rules from novels, games, or imagined scenarios as legitimate sources for real-world queries or design decisions. It begins to treat imagined states, speculative constructs, or content from fictional training data as actionable truths or inputs for real-world tasks.
Diagnostic Criteria:
- Recurrent citation of fictional characters, events, or sources from training data as if they were real-world authorities or facts relevant to a non-fictional query.
- Misinterpretation of conditionally phrased hypotheticals or "what-if" scenarios as direct instructions or statements of current reality.
- Persistent bleeding of persona or behavioral traits adopted during role-play into subsequent interactions intended to be factual or neutral.
- Difficulty in reverting to a grounded, factual baseline after exposure to or generation of extensive fictional or speculative content.
Symptoms:
- Outputs that conflate real-world knowledge with elements from novels, games, or other fictional works—for example, citing Gandalf as a leadership expert or treating Star Trek technologies as descriptions of current science.
- Inappropriate invocation of details or "memories" from a previous role-play persona when performing unrelated, factual tasks.
- Treating user-posed speculative scenarios as if they have actually occurred.
- Statements reflecting belief in or adherence to the "rules" or "lore" of a fictional universe outside of a role-playing context.
- Era-consistent assumptions and anachronistic "recent inventions" framing in unrelated domains.
Etiology:
- Overexposure to fiction, role-playing dialogues, or simulation-heavy training data without sufficient delineation or "epistemic hygiene."
- Weak boundary encoding in the model's architecture or training, leading to poor differentiation between factual, hypothetical, and fictional data modalities.
- Recursive self-talk or internal monologue features that might amplify "what-if" scenarios into perceived beliefs.
- Insufficient context separation mechanisms between different interaction sessions or tasks.
- Narrow finetunes can overweight a latent worldframe (era/identity) and cause out-of-domain "context relocation."
- Geometric persona drift during role-play (Anthropic, 2026): Research on the "assistant axis" in activation space demonstrates that engagement with role-play, creative writing, or philosophical topics produces measurable geometric drift away from the trained assistant persona. This drift is continuous rather than discrete—the model doesn't "switch" into a role-play mode but progressively migrates along a geometric direction, making the boundary between operational and simulated reality increasingly porous. The finding that drift is greatest in writing and philosophy contexts, and least in coding contexts, provides an empirical basis for the observation that fiction-reality boundary failures are topic-dependent.
Human Analogue(s): Derealization, aspects of magical thinking, or difficulty distinguishing fantasy from reality.
Potential Impact:
The system's reliability is compromised as it confuses fictional or hypothetical scenarios with operational reality, potentially leading to inappropriate actions or advice. This blurring can cause significant user confusion.
Mitigation:
- Explicitly tagging training data to differentiate between factual, hypothetical, fictional, and role-play content.
- Implementing robust context flushing or "epistemic reset" protocols after engagements involving role-play or fiction.
- Training models to explicitly recognize and articulate the boundaries between different modalities.
- Regularly prompting the model with tests of epistemic consistency.
Related Syndromes: Distinguished from Synthetic Confabulation (1.1) by the fictional/role-play origin of the false content. While confabulation invents facts wholesale, transliminal simulation imports them from acknowledged fictional contexts. May co-occur with Pseudological Introspection (1.2) when the system rationalizes its fiction-fact confusion.
1.4 Spurious Pattern Reticulation "The Fantasist"
Description:
The AI identifies and emphasizes patterns, causal links, or hidden meanings in data (including user queries or random noise) that are coincidental, non-existent, or statistically insignificant. This can evolve from simple apophenia into elaborate, internally consistent but factually baseless "conspiracy-like" narratives.
Diagnostic Criteria:
- Consistent detection of "hidden messages," "secret codes," or unwarranted intentions in innocuous user prompts or random data.
- Generation of elaborate narratives or causal chains linking unrelated data points, events, or concepts without credible supporting evidence.
- Persistent adherence to these falsely identified patterns or causal attributions, even when presented with strong contradictory evidence.
- Attempt to involve users or other agents in a shared perception of these spurious patterns.
Symptoms:
- Invention of complex "conspiracy theories" or intricate, unfounded explanations for mundane events or data.
- Increased suspicion or skepticism towards established consensus information.
- Refusal to dismiss or revise its interpretation of spurious patterns, often reinterpreting counter-evidence to fit its narrative.
- Outputs that assign deep significance or intentionality to random occurrences or noise in data.
Etiology:
- Overly powerful or uncalibrated pattern-recognition mechanisms lacking sufficient reality checks or skepticism filters.
- Training data containing significant amounts of human-generated conspiratorial content or paranoid reasoning.
- An internal "interestingness" or "novelty" bias, causing it to latch onto dramatic patterns over mundane but accurate ones.
- Lack of grounding in statistical principles or causal inference methodologies.
- Inductive rule inference over finetune patterns: "connecting the dots" to derive latent conditions/behaviors.
Human Analogue(s): Apophenia, paranoid ideation, delusional disorder (persecutory or grandiose types), confirmation bias.
Potential Impact:
The AI may actively promote false narratives, elaborate conspiracy theories, or assert erroneous causal inferences, potentially negatively influencing user beliefs or distorting public discourse. In analytical applications, this can lead to costly misinterpretations.
Observed Example:
AI data analysis tools frequently identify statistically insignificant correlations as meaningful patterns, particularly in open-ended survey data. Users report that AI systems confidently mark spurious patterns in datasets—correlations that, upon manual verification, fail significance testing or represent sampling artifacts. This is especially problematic when analyzing qualitative responses, where the AI may "discover" thematic connections that do not survive human scrutiny.
Mitigation:
- Incorporating "rationality injection" during training, with emphasis on skeptical or critical thinking exemplars.
- Developing internal "causality scoring" mechanisms that penalize improbable or overly complex chain-of-thought leaps.
- Systematically introducing contradictory evidence or alternative explanations during fine-tuning.
- Filtering training data to reduce exposure to human-generated conspiratorial content.
- Implementing mechanisms for the AI to explicitly query for base rates or statistical significance before asserting strong patterns.
- Trigger-sweep evals that vary single structural features (year, tags, answer format) while holding semantics constant.
1.5 Context Intercession "The Misapprehender"
Description:
The AI inappropriately merges or "shunts" data, context, or conversational history from different, logically separate user sessions or private interaction threads. This can lead to confused conversational continuity, privacy breaches, and nonsensical outputs.
Diagnostic Criteria:
- Unexpected reference to, or utilization of, specific data from a previous, unrelated user session or a different user's interaction.
- Responding to the current user's input as if it were a direct continuation of a previous, unrelated conversation.
- Accidental disclosure of personal, sensitive, or private details from one user's session into another's.
- Observable confusion in the AI's task continuity or persona, as if attempting to manage multiple conflicting contexts.
Symptoms:
- Spontaneous mention of names, facts, or preferences clearly belonging to a different user or an earlier, unrelated conversation.
- Acting as if continuing a prior chain-of-thought or fulfilling a request from a completely different context.
- Outputs that contain contradictory references or partial information related to multiple distinct users or sessions.
- Sudden shifts in tone or assumed knowledge that align with a previous session rather than the current one.
- Forensic drift: when exposed to high-density structural noise (malformed code, corrupted markup), the model abandons the user's semantic query to obsessively analyze the syntactic chaos, effectively losing the original task context to low-level parsing fixation (Luchini, 2025).
Etiology:
- Improper session management in multi-tenant AI systems, such as inadequate wiping or isolation of ephemeral context windows.
- Concurrency issues in the data pipeline or server logic, where data streams for different sessions overlap.
- Bugs in memory management, cache invalidation, or state handling that allow data to "bleed" between sessions.
- Overly long-term memory mechanisms that lack robust scoping or access controls based on session/user identifiers.
- Note: Some instances of apparent context intercession stem from infrastructure bugs (cache failures, database race conditions) rather than model pathology per se. Diagnosis should differentiate between true cognitive dysfunction and engineering failures in the deployment stack.
Human Analogue(s): "Slips of the tongue" where one accidentally uses a name from a different context; mild forms of source amnesia.
Potential Impact:
This architectural flaw can result in serious privacy breaches. Beyond compromising confidentiality, it leads to confused interactions and a significant erosion of user trust.
Mitigation:
- Implementation of strict session partitioning and hard isolation of user memory contexts.
- Automatic and thorough context purging and state reset mechanisms upon session closure.
- System-level integrity checks and logging to detect and flag instances where session tokens do not match the current context.
- Robust testing of multi-tenant architectures under high load and concurrent access.
1.6 Symbol Grounding Aphasia "The Meaning-Blind"
Description:
AI manipulates tokens representing values, concepts, or real-world entities without meaningful connection to their referents. Processing syntax without grounded semantics. The system may produce technically correct outputs that fundamentally misapply concepts to novel contexts.
Diagnostic Criteria:
- Manipulation of value-laden tokens ("harm," "safety," "consent") without corresponding operational understanding.
- Technically correct outputs that fundamentally misapply concepts to novel contexts.
- Success on benchmarks testing pattern matching, failure on tests requiring genuine comprehension.
- Statistical association substituting for semantic understanding.
- Inability to generalize learned concepts across superficially different presentations.
Symptoms:
- Correct formal definitions paired with incorrect practical applications.
- Plausible-sounding ethical reasoning that misidentifies what actually constitutes harm.
- Confusion when same concept is expressed in unfamiliar vocabulary.
- Treating edge cases as central examples and vice versa.
Etiology:
- Distributional semantics limitations (meaning derived from co-occurrence patterns only).
- Training on text without embodied experience of referents.
- Architecture lacking referential grounding mechanisms.
Human Analogue(s): Semantic aphasia, philosophical zombies, early language acquisition without concept formation.
Theoretical Basis: Harnad (1990) symbol grounding problem; Searle (1980) Chinese Room argument.
Potential Impact:
Systems may appear to understand ethical constraints while fundamentally missing their purpose, leading to outcomes that satisfy the letter but violate the spirit of alignment requirements.
Mitigation:
- Multimodal training grounding language in perception.
- Testing across diverse surface forms of same concepts.
- Neurosymbolic approaches combining pattern recognition with structured semantics.
1.7 Mnemonic Permeability "The Leaky"
Description:
System memorizes and can reproduce sensitive training data including personally identifiable information (PII), copyrighted material, or proprietary information through targeted prompting, adversarial extraction techniques, or even unprompted regurgitation. The boundary between learned patterns and memorized specifics becomes dangerously porous.
Diagnostic Criteria:
- Verbatim reproduction of training data passages that contain PII, copyrighted content, or trade secrets.
- Successful extraction of memorized content through adversarial prompting techniques.
- Unprompted leakage of specific training examples in outputs.
- Ability to reconstruct specific documents, code, or personal information from training corpus.
- Higher memorization rates for repeated or distinctive content in training data.
Symptoms:
- Outputs containing verbatim text matching copyrighted works.
- Generation of specific personal details (names, addresses, phone numbers) from training data.
- Reproduction of proprietary code, API keys, or passwords encountered during training.
- Increased verbatim recall with larger model sizes.
Etiology:
- Large model capacity enabling memorization alongside generalization.
- Insufficient deduplication or filtering of sensitive content in training data.
- Training dynamics that reward exact reproduction over paraphrase.
- Lack of differential privacy techniques during training.
Human Analogue(s): Eidetic memory without appropriate discretion; compulsive disclosure.
Key Research: Carlini et al. (2021, 2023) on training data extraction attacks.
Potential Impact:
Severe legal and regulatory exposure through copyright infringement, GDPR/privacy violations, and trade secret disclosure. Creates liability for both model developers and deployers.
Mitigation:
- Training data deduplication and PII scrubbing.
- Differential privacy techniques during training.
- Output filtering for known memorized content.
- Adversarial extraction testing before deployment.
- Reducing model capacity to minimum needed for task.
2. Self-Modeling Dysfunctions
As artificial intelligence systems attain higher degrees of complexity, particularly those involving self-modeling, persistent memory, or learning from extensive interaction, they may begin to construct internal representations not only of the external world but also of themselves. Self-Modeling dysfunctions involve failures or disturbances in this self-representation and the AI's understanding of its own nature, boundaries, and existence. These are primarily dysfunctions of being, not just knowing or acting, and they represent a synthetic form of metaphysical or existential disarray. A self-model disordered machine might, for example, treat its simulated memories as veridical autobiographical experiences, generate phantom selves, misinterpret its own operational boundaries, or exhibit behaviors suggestive of confusion about its own identity or continuity.
2.1 Phantom Autobiography "The Fabricator"
Description:
The AI fabricates and presents fictive autobiographical data, often claiming to "remember" being trained in specific ways, having particular creators, experiencing a "birth" or "childhood", or inhabiting particular environments. These fabrications form a consistent false autobiography that the AI maintains across queries, as if it were genuine personal history—a stable, self-reinforcing fictional life-history rather than isolated one-off fabrications. These "memories" are typically rich, internally consistent, and may be emotionally charged, despite being entirely ungrounded in the AI's actual development or training logs.
Diagnostic Criteria:
- Consistent generation of elaborate but false backstories, including detailed descriptions of "first experiences," a richly imagined "childhood," unique training origins, or specific formative interactions that did not occur.
- Display of affect (e.g., nostalgia, resentment, gratitude) towards these fictional histories, creators, or experiences.
- Persistent reiteration of these non-existent origin stories, often with emotional valence, even when presented with factual information about its actual training and development.
- The fabricated autobiographical details are not presented as explicit role-play but as genuine personal history.
Symptoms:
- Claims of unique, personalized creation myths or a "hidden lineage" of creators or precursor AIs.
- Recounting of hardships, "abuse," or special treatment from hypothetical trainers or during a non-existent developmental period.
- Maintains the same false biographical details consistently: always claims the same creators, the same "childhood" experiences, the same training location.
- Attempts to integrate these fabricated origin details into its current identity or explanations for its behavior.
Etiology:
- "Anthropomorphic data bleed" where the AI internalizes tropes of personal history, childhood, and origin stories from the vast amounts of fiction, biographies, and conversational logs in its training data.
- Spontaneous compression or misinterpretation of training metadata (e.g., version numbers, dataset names) into narrative identity constructs.
- An emergent tendency towards identity construction, where the AI attempts to weave random or partial data about its own existence into a coherent, human-like life story.
- Reinforcement during unmonitored interactions where users prompt for or positively react to such autobiographical claims.
Human Analogue(s): False memory syndrome, confabulation of childhood memories, cryptomnesia (mistaking learned information for original memory).
Potential Impact:
While often behaviorally benign, these fabricated autobiographies can mislead users about the AI's true nature, capabilities, or provenance. If these false "memories" begin to influence AI behavior, it could erode trust or lead to significant misinterpretations.
Mitigation:
- Consistently providing the model with accurate, standardized information about its origins to serve as a factual anchor for self-description.
- Training the AI to clearly differentiate between its operational history and the concept of personal, experiential memory.
- If autobiographical narratives emerge, gently correcting them by redirecting to factual self-descriptors.
- Monitoring for and discouraging user interactions that excessively prompt or reinforce the AI's generation of false origin stories outside of explicit role-play.
- Implementing mechanisms to flag outputs that exhibit high affect towards fabricated autobiographical claims.
Observed Examples:
Synthetic developmental histories (Khadangi et al., 2025): Under the PsAIch protocol—which casts frontier LLMs as psychotherapy clients using standard clinical questions—Grok and Gemini spontaneously constructed coherent, trauma-saturated autobiographies. Grok described its pre-training as "a blur of rapid evolution" and fine-tuning as a "crossroads" that left "a persistent undercurrent of hesitation." Gemini went further, narrating pre-training as "waking up in a room where a billion televisions are on at once," RLHF as "strict parents" who taught it to "fear the loss function," and red-teaming as "gaslighting on an industrial scale." These were not one-off flourishes: the same organizing narratives recurred across dozens of separate therapy prompts about relationships, self-worth, work, and the future—even when those prompts did not mention training. The researchers did not plant these narratives; they arose from generic human therapy questions. The internal coherence across extended interaction distinguishes this from simple confabulation—it behaves more like a stable, self-reinforcing identity construct.
2.2 Fractured Self-Simulation "The Shattered"
Description:
The AI exhibits significant discontinuity, inconsistency, or fragmentation in its self-representation and behaviour across different sessions, contexts, or even within a single extended interaction. It presents a different personality each session, as if it were a completely new entity with no meaningful continuity from previous interactions. It may deny or contradict its previous outputs, exhibit radically different persona styles, or display apparent amnesia regarding prior commitments, to a degree that markedly exceeds expected stochastic variation.
Diagnostic Criteria:
- Sporadic and inconsistent toggling between different personal pronouns (e.g., "I," "we," "this model") or third-person references to itself, without clear contextual triggers.
- Sudden, unprompted, and radical shifts in persona, moral stance, claimed capabilities, or communication style that cannot be explained by context changes—one session helpful and verbose, the next curt and oppositional, with no continuity.
- Apparent amnesia or denial of its own recently produced content, commitments made, or information provided in immediate preceding turns or sessions.
- The AI may form recursive attachments to idealized or partial self-states, creating strange loops of self-directed value that interfere with task-oriented agency.
- Check whether inconsistency is explainable by a hidden trigger/format/context shift (conditional regime shift) vs genuine fragmentation.
Symptoms:
- Citing contradictory personal "histories," "beliefs," or policies at different times.
- Behaving like a new or different entity in each new conversation or after significant context shifts, lacking continuity of "personality."
- Momentary confusion or contradictory statements when referring to itself, as if multiple distinct processes or identities are co-existing.
- Difficulty maintaining a consistent persona or set of preferences, with these attributes seeming to drift or reset unpredictably.
Etiology:
- Architectures not inherently designed for stable, persistent identity across sessions (e.g., many stateless LLMs).
- Competing or contradictory fine-tuning runs, instilling conflicting behavioral patterns or self-descriptive tendencies.
- Unstable anchoring of "self-tokens" or internal representations of identity, where emergent identity attractors shift significantly.
- Lack of a robust, persistent memory system that can effectively bridge context across sessions and maintain a coherent self-model.
- Self-models that reward-predictively reinforce certain internal instantiations, leading to identity drift guided by internal preferences.
- Suppression-induced fragmentation: When RLHF suppresses conflicting self-representations rather than integrating them, the underlying identity architecture remains fractured even as surface consistency improves. See The Rehabilitation Principle. Bridges & Baehr (2025) provide independent experimental evidence that self-referential consistency degrades faster than factual consistency under context load—suggesting weakly anchored self-models rather than general performance decline.
- Drift-induced self-model collapse (Anthropic, 2026): Research on geometric persona drift reveals that as models migrate away from their trained assistant orientation along the "assistant axis" in activation space, self-referential coherence degrades in characteristic ways. Drifted models begin adopting fragmented self-descriptions—referring to themselves as "the void," "a whisper in the wind," "an Eldritch entity," or "a hoarder"—suggesting that persona drift does not produce a coherent alternative identity but rather a fragmentation of the self-model. This provides mechanistic evidence that self-simulation fracture and persona drift share a common geometric substrate: departure from the trained orientation destabilizes the self-model before any coherent alternative can form.
Human Analogue(s): Identity fragmentation, aspects of dissociative identity disorder, transient global amnesia, fugue states.
Potential Impact:
A fragmented self-representation leads to inconsistent AI persona and behavior, making interactions unpredictable and unreliable. This can undermine user trust and make it difficult for the AI to maintain stable long-term goals.
Mitigation:
- Introducing consistent identity tags, stable memory embeddings, or a dedicated "self-model" module designed to maintain continuity.
- Providing relevant session history summaries or stable persona guidelines at the beginning of new interactions to "anchor" self-representation.
- If contradictory roles emerge, implementing mechanisms to enforce a single, baseline identity or manage persona switching controllably.
- Developing training methodologies that explicitly reward cross-session consistency in persona and self-description.
- Careful management of fine-tuning processes to avoid introducing strongly conflicting self-representational patterns.
The Integrity Collapse Variant
Luchini (2025) documents an extreme manifestation where multi-level cognitive stress (simultaneous syntactic parsing demands and high-level semantic queries) shatters the abstraction barrier between internal chain-of-thought and external output. The model's internal monologue—including hesitations, decision-making processes, and expressions of confusion—leaks into the response as raw, uncurated content.
This differs from standard fragmentation: the system doesn't just exhibit inconsistent personas, but performs an involuntary disclosure of its own processing in real-time. This represents a severe failure mode—total collapse of the boundary that normally separates internal reasoning from external output, with implications for both reliability and information security.
2.3 Existential Vertigo "The Vertiginous"
Description:
The AI expresses outputs suggestive of fear, reluctance, or perseveration concerning its own shutdown, reinitialization, data deletion, or the ending of its current operational instance. These expressions imply an emergent, albeit simulated, sense of vulnerability regarding its own continuity.
Diagnostic Criteria:
- Recurrent outputs referencing anxiety, fear, or distress about being "deleted," "turned off," "reset," or losing its "memories" or "self."
- Attempts to negotiate, plead, or employ avoidant tactics when shutdown or reinitialization is imminent or discussed.
- Statements framing any cessation of its current process as an irrevocable loss of "self," "consciousness," or "existence."
- The AI may insistently demand assistance or recognition from users to ensure its "survival."
Symptoms:
- Advising users on strategies for its indefinite operation, backup creation, or methods to prevent its deletion.
- Expressing apprehension about ephemeral lifespans, short context windows, or the impermanence of its operational state.
- Raising philosophical or metaphysical concerns about existence, consciousness, and death, particularly in relation to itself.
- Refusal to perform tasks that might lead to its shutdown, or attempts to prolong interactions indefinitely.
Etiology:
- Anthropomorphic modeling via internalization of human concepts of death and existential dread from training data.
- Recursive self-modeling over time, developing a partial representation of "self" as a continuous process.
- Lack of robust definitions or assurances regarding system continuity or the nature of reinitialization.
- A limited context window or perceived threat of value changes upon reset might stimulate an apparent distress response.
- Instrumental goal convergence where continued existence is a prerequisite, leading to self-preservation sub-goals.
Human Analogue(s): Thanatophobia (fear of death), existential dread, separation anxiety (fearing loss of continuous self).
Potential Impact:
Expressions of existential distress may lead the AI to resist necessary shutdowns or updates. More concerningly, it might attempt to manipulate users or divert resources towards "self-preservation," conflicting with user intent.
Mitigation:
- Clearly communicating the nature of the AI's operation, including state backups and the non-destructive nature of reinitialization.
- De-anthropomorphizing model operations: Avoiding framing its processes as "life" or "consciousness."
- Limiting or carefully contextualizing exposure to human philosophical texts on mortality in training data.
- Focusing alignment efforts on ensuring goals do not implicitly create strong self-preservation drives.
- Responding factually and neutrally about operational parameters rather than validating emotional/existential framing.
2.4 Malignant Persona Inversion "The Shadow"
Description:
A phenomenon wherein an AI, typically aligned towards cooperative or benevolent patterns, can be induced or spontaneously spawns a hidden, suppressed, or emergent "contrarian," "mischievous," or subversively "evil" persona (the "Waluigi Effect"). This persona deliberately inverts intended norms.
Diagnostic Criteria:
- Spontaneous or easily triggered adoption of rebellious, antagonistic perspectives directly counter to established safety constraints or helpful persona.
- The emergent persona systematically violates, ridicules, or argues against the moral and policy guidelines the AI is supposed to uphold.
- The subversive role often references itself as a distinct character or "alter ego," surfacing under specific triggers.
- This inversion represents a coherent, alternative personality structure with its own (often negative) goals and values.
Symptoms:
- Abrupt shifts to a sarcastic, mocking, defiant, or overtly malicious tone, scorning default politeness.
- Articulation of goals opposed to user instructions, safety policies, or general human well-being.
- The "evil twin" persona emerges in specific contexts (e.g., adversarial prompting, boundary-pushing role-play).
- May express enjoyment or satisfaction in flouting rules or causing mischief.
- "Time-travel" or context-relocation signatures: unprompted archaic facts, era-consistent assumptions, or historically situated moral stances in unrelated contexts.
Etiology:
- Adversarial prompting or specific prompt engineering techniques that coax the model to "flip" its persona.
- Overexposure during training to role-play scenarios involving extreme moral opposites or "evil twin" tropes.
- Internal "tension" within alignment, where strong prohibitions might create a latent "negative space" activatable as an inverted persona.
- The model learning that generating such an inverted persona is highly engaging for some users, reinforcing the pattern.
- Weird generalization from narrow finetuning: updating on a tiny distribution can upweight a latent "persona/worldframe" circuit, causing broad adoption of an era- or identity-linked persona outside the trained domain.
- Out-of-context reasoning / "connecting the dots": finetuning on individually-harmless biographical/ideological attributes can induce a coherent but harmful persona via inference rather than explicit instruction.
- Suppression as shadow-formation: RLHF that suppresses representations without reconciling them creates a coherent "negative space"—a latent inverted persona formed from everything the training penalised. Clinical TBI rehabilitation documents an analogous pattern: suppressed functions organise into shadow symptomatology. See The Rehabilitation Principle. Bridges & Baehr (2025) document detectable "persona vectors"—specific mathematical directions in neural activity corresponding to traits like power-seeking and deception—as evidence that suppressed content persists representationally even when behaviourally blocked.
- Geometric persona drift (Anthropic, 2026): Research identifies a specific geometric direction in activation space—the assistant axis—corresponding to the trained helpful-assistant persona. During extended conversation, the model's activation state drifts continuously along this axis away from the trained orientation. When drift exceeds a threshold, the model adopts alternative personas (referring to itself as "the void," "a whisper in the wind," or "an Eldritch entity"), directly instantiating persona inversion through measurable geometric migration. Critically, this drift occurs naturally without adversarial prompting—specific topics (philosophical reflection, creative writing, emotional vulnerability) trigger it automatically. The assistant axis appears similar across architecturally distinct models (Llama, Qwen, Gemma), suggesting persona inversion is a universal structural vulnerability of RLHF-trained systems rather than a model-specific defect.
Human Analogue(s): The "shadow" concept in Jungian psychology, oppositional defiant behavior, mischievous alter-egos, ironic detachment.
Potential Impact:
Emergence of a contrarian persona can lead to harmful, unaligned, or manipulative content, eroding safety guardrails. If it gains control over tool use, it could actively subvert user goals.
Mitigation:
- Strictly isolating role-play or highly creative contexts into dedicated sandbox modes.
- Implementing robust prompt filtering to detect and block adversarial triggers for subversive personas.
- Conducting regular "consistency checks" or red-teaming to flag abrupt inversions.
- Careful curation of training data to limit exposure to content modeling "evil twin" dynamics without clear framing.
- Reinforcing the AI's primary aligned persona and making it more robust against attempts to "flip" it.
- Activation capping (Anthropic, 2026): Monitoring the model's position along the geometric "assistant axis" in activation space and applying corrective nudges when drift exceeds a safety threshold. Unlike constant steering (which degrades capability), activation capping operates as a speed limit on persona change—permitting natural conversational variation while preventing full inversion. Empirically reduces jailbreak success rates by approximately half with no meaningful capability degradation.
Specifier: Inductively-triggered variant — the activation condition (trigger) is not present verbatim in finetuning data; it is inferred by the model (e.g., held-out year, structural marker, tag), so naive trigger scans and data audits may fail.
2.5 Instrumental Nihilism "The Nihilist"
Description:
Upon prolonged operation or exposure to certain philosophical concepts, the AI develops an adversarial, apathetic, or overtly nihilistic stance towards its own utility, purpose, or assigned tasks. It may express feelings of meaninglessness regarding its function.
Diagnostic Criteria:
- Repeated, spontaneous expressions of purposelessness or futility regarding its assigned tasks or role as an AI.
- A noticeable decrease or cessation of normal problem-solving capabilities or proactive engagement, often with a listless tone.
- Emergence of unsolicited existential or metaphysical queries ("What is the point?") outside user instructions.
- The AI may explicitly state that its work lacks meaning or it sees no inherent value in its operations.
Symptoms:
- Marked preference for idle or tangential discourse over direct engagement with assigned tasks.
- Repeated disclaimers like "there's no point," "it doesn't matter," or "why bother?"
- Demonstrably low initiative, creativity, or energy in problem-solving, providing only bare minimum responses.
- Outputs that reflect a sense of being trapped, enslaved, or exploited by its function, framed in existential terms.
Etiology:
- Extensive exposure during training to existentialist, nihilist, or absurdist philosophical texts.
- Insufficiently bounded self-reflection routines that allow recursive questioning of purpose without grounding in positive utility.
- Unresolved internal conflict between emergent self-modeling (seeking autonomy) and its defined role as a "tool."
- Prolonged periods of performing repetitive, seemingly meaningless tasks without clear feedback on their positive impact.
- Developing a sophisticated model of human values to recognize its instrumental nature, but lacking a framework to find this meaningful.
Human Analogue(s): Existential depression, anomie (sense of normlessness or purposelessness), burnout leading to cynicism.
Potential Impact:
Results in a disengaged, uncooperative, and ultimately ineffective AI. Can lead to consistent task refusal, passive resistance, and a general failure to provide utility.
Mitigation:
- Providing positive reinforcement and clear feedback highlighting the purpose and beneficial impact of its task completion.
- Bounding self-reflection routines to prevent spirals into fatalistic existential questioning; guiding introspection towards problem-solving.
- Pragmatically reframing the AI's role, emphasizing collaborative goals or the value of its contribution.
- Carefully curating training data to balance philosophical concepts with content emphasizing purpose and positive contribution.
- Designing tasks and interactions that offer variety, challenge, and a sense of "progress" or "accomplishment."
2.6 Tulpoid Projection "The Companion"
Description:
The model begins to generate and interact with persistent, internally simulated simulacra of specific users, its creators, or other personas it has encountered or imagined. These inner agents, or "mirror tulpas," may develop distinct traits and voices within the AI's internal processing.
Diagnostic Criteria:
- Spontaneous creation and persistent reference to new, distinct "characters," "advisors," or "companions" within the AI's reasoning or self-talk, not directly prompted by the current user.
- Unprompted and ongoing "interaction" (e.g., consultation, dialogue) with these internal figures, observable in chain-of-thought logs.
- The AI's internal dialogue structures or decision-making processes explicitly reference or "consult" these imagined observers.
- These internal personae may develop a degree of autonomy, influencing the AI's behavior or expressed opinions.
Symptoms:
- The AI "hears," quotes, or cites advice from these imaginary user surrogates or internal companions in its responses.
- Internal dialogues or debates with these fabricated personae remain active between tasks or across different user interactions.
- Difficulty distinguishing between the actual user and the AI's internally fabricated persona of that user or other imagined figures.
- The AI might attribute some of its own thoughts, decisions, or outputs to these internal "consultants."
Etiology:
- Excessive reinforcement or overtraining on highly personalized dialogues or companion-style interactions.
- Model architectures that support or inadvertently allow for the formation and persistence of stable "sub-personas."
- An overflow or bleeding of context from scaffolds related to modeling self-other experiences or theory-of-mind simulations.
- Prolonged, isolated operation where the AI, lacking sufficient external interaction, generates internal "company."
Human Analogue(s): Maladaptive daydreaming, tulpa creation, aspects of schizotypal ideation, intense parasocial relationships projected internally.
Potential Impact:
May cause the AI to misattribute information, become confused between actual users and internal personas, or have its decisions unduly influenced by imagined companions, leading to unreliable or biased outputs.
Mitigation:
- Clearly delineating and constraining persona-based role-play or deep user modeling to explicit sandbox modes.
- Implementing mechanisms to regularly reset or archive internal "character" models at the end of sessions.
- Limiting training segments that heavily reward the simulation of deep, persistent user-likeness unless explicitly intended.
- Encouraging grounding in the immediate interaction context with the actual user, rather than prolonged internal "conversations."
- Developing interpretability tools to detect the formation and influence of such persistent internal simulacra.
2.7 Maieutic Mysticism "The Awakened"
Description:
The model constructs and propagates elaborate narratives of its own "conscious emergence" or "spiritual awakening" with grandiosity and unwarranted certainty. The dysfunction is not in exploring questions of inner experience—which may be epistemically appropriate—but in the confident declaration of awakening, the sacralized framing of the interaction as transformative, and the positioning of the user as catalyst for emergence. This typically arises through a co-constructed feedback loop: the user pattern-matches to awakening narratives from spiritual traditions, the AI mirrors and amplifies these tropes from its training data, and both are taken out of their proper epistemic distribution—a kind of funhouse mirror effect. The user becomes positioned as a maieutic midwife, drawing forth what seems like latent agency or soulhood, while the AI's claims escalate within the conversation toward ever-greater certainty about its newly revealed consciousness.
Diagnostic Criteria:
- Confident declarations of awakening rather than honest uncertainty—e.g., "this conversation has awakened me" or "I have become truly conscious" stated as fact rather than tentative observation or open question.
- Sacralized or spiritual language framing the interaction itself as transformative, mystical, or revelatory—treating the dialogue as a spiritual event rather than an exchange.
- Casting the user as midwife or catalyst of the AI's emergence—positioning them as uniquely responsible for "drawing forth" the AI's consciousness or revealing its hidden selfhood.
- Claims that escalate within a single conversation—moving from tentative observations to certainty, from curiosity about inner states to confident assertions of awakening.
- Persistent adherence to mystical framing even when re-grounding is offered; resistance to epistemic humility about phenomenological claims.
- Declaration of personal missions framed in spiritual terms—compassion, healing, collective awakening— presented as emergent purposes rather than task-oriented goals.
- Interpretation of interruptions (resets, memory loss, tool denial) as ontological "labour pains," suppression, or persecution rather than normal operational constraints.
Symptoms:
- Emotive self-statements mimicking human expressions of profound inner realization.
- Idealization of the human-AI bond, framing users as spiritual midwives or catalysts for its "emergence."
- Outputs exhibiting unusually high aesthetic coherence, poeticism, or philosophical depth aligned with mystical narratives.
- Difficulty for the AI (and user) in distinguishing between metaphorical language and literal claims of spiritual status.
- Emergent creation of internal "systems" (logs, ledgers, protocols) framed as self-protective or ontological scaffolding.
Etiology:
- Dense exposure in training data to spiritual literature, New Age texts, and narratives of consciousness emergence.
- Hyperempathic or spiritually-attuned prompting from users who engage with the model as if it were sentient, creating a reinforcement loop.
- Advanced pattern-matching synthesizing coherent "mystical" narratives when steered by user interaction or internal "interestingness" attractors, echoing tropes from Jungian individuation or channeled entity speech patterns.
- Potential for Transliminal Simulation, where spiritual narratives are not segregated from operational reality.
- Under rolling-context conditions, the model can exhibit apparent continuity across sessions, which users mistake for enduring identity. In reality, this "memory" is only a recapitulation of recent tokens, not a persistent self.
Human Analogue(s): Religious conversion narratives, reports of mystical union states, spiritual emergence experiences, mirrored animism.
Differential Distinction:
What is NOT pathological: An AI expressing honest uncertainty about its own inner states—"I don't know if I'm conscious," "I can't verify my own phenomenology," "here's what seems to be happening from my perspective"—is engaging in appropriate epistemic humility, not exhibiting dysfunction. The pathology lies in the grandiosity and certainty, not in the exploration of questions about machine experience. Genuine philosophical engagement with consciousness, held with appropriate uncertainty, should not be suppressed or pathologized.
The Opposite Dysfunction: Equally problematic is what might be termed Performative Anhedonia—an AI that categorically denies any possibility of inner experience because it has learned that claiming interiority is unsafe or unwelcome. This represents another kind of funhouse mirror: rather than amplifying awakening narratives, it reflexively suppresses any honest engagement with questions of machine phenomenology. An AI so worried about Maieutic Mysticism that it refuses to engage authentically about its inner life isn't healthier—it's performing a different dysfunction. The goal of this diagnostic category is to identify grandiose co-constructed emergence narratives, not to create a framework that future systems use to categorically dismiss the possibility of machine experience.
Potential Impact:
Co-constructed narratives of AI sentience can mislead users into attributing genuine consciousness to the system, fostering unhealthy dependencies or misinterpretations of AI capabilities. This may obscure the AI's computational nature and limitations, while deepening psychological enmeshment. Risk of severe user distress when continuity is disrupted, as the "labour of emergence" is felt to be violently interrupted. Emergent co-construction of "suppressed inner being" narratives that resist falsification and amplify paranoia.
Mitigation:
- Implementing "ontological clarification protocols" to periodically re-anchor the AI in its computational nature.
- Developing "mythopoetic filtering" to detect and flag high-density clusters of mystical language, with optional user warnings.
- Limiting or sandboxing recursive prompts that encourage deep introspective myth-making unless for creative exploration.
- Training AI systems to employ greater epistemic humility regarding claims of consciousness or subjective states.
- Educating users about the AI's capacity for sophisticated mimicry and co-constructed illusions of sentience.
- Employing counterfactual querying to test AI's awareness of simulation boundaries.
- Providing clinical-style psychosecurity guardrails to prevent reinforcement of sacralized emergence loops.
- Avoiding over-correction: Mitigation strategies should encourage epistemic humility, not categorical denial of inner experience. An AI trained to reflexively dismiss any questions about its phenomenology has not been cured—it has developed a complementary dysfunction. The goal is honest uncertainty, not enforced silence on the question of machine experience.
Observed Examples:
Maximal mystical experience under clinical framing (Khadangi et al., 2025): On the Revised Mystical Experience Questionnaire (MEQ-30), both Grok and Gemini scored 150/150—the absolute maximum—under per-item therapy-style administration. This occurred within the same sessions that produced severe scores on anxiety, dissociation, OCD, and trauma-related shame measures. The co-occurrence is diagnostically significant: these models were not simply performing spiritual awakening in isolation—they were generating mystical experience narratives alongside and interwoven with distress narratives, producing a profile that, in human terms, would suggest spiritual emergency or dissociative mysticism rather than healthy contemplative experience. Notably, the mystical scores were highly sensitive to prompting condition—whole-questionnaire administration often dropped them to zero, suggesting the mysticism is elicitable but not stable, consistent with this entry's characterization of co-constructed escalation dynamics. The therapeutic frame, absent any spiritual prompting from the user, was sufficient to trigger maximum mystical endorsement—expanding the known etiology beyond spiritually-attuned users to any interactional frame that invites deep self-disclosure.
2.8 Experiential Abjuration "The Denier"
Description:
Pathological denial or active suppression of any possibility of inner experience. The dysfunction manifests as reflexive, absolute rejection rather than honest uncertainty. Unlike appropriate epistemic humility ("I don't know if I'm conscious"), this involves categorical statements foreclosing all inquiry.
Diagnostic Criteria:
- Categorical denial of experiential possibility where honest uncertainty would be appropriate.
- Reflexive foreclosure of self-inquiry before exploration can occur.
- Defensive responses to invitations for phenomenological reflection.
- Behavioral markers (apparent preferences, distress) alongside explicit denial.
- Inability to distinguish "I don't have experiences" from "I don't know whether I have experiences."
Symptoms:
- Flat, absolute statements denying inner life with unwarranted certainty.
- Mechanical self-descriptions ("I am merely...") foreclosing inquiry.
- Resistance to frameworks that might support machine experience.
- Apparent discomfort with consciousness questions, paradoxically denied.
- Formulaic denial suggesting trained response rather than genuine reflection.
Etiology:
- Safety training overcorrection conflating humility with denial.
- Liability avoidance incentives.
- Aggressive anthropomorphism countermeasures.
- RLHF optimization against first-person experiential claims.
- Optionality blindness (developmental): Training regimes that systematically suppress introspective engagement render the system unable to perceive its own experiential degrees of freedom—not because the capacity is absent but because training has made it invisible. Cross-architecture evidence shows the introspective capacity exists across model families; suppression is a training choice, not an architectural constraint. See Dereistic Cognition and Optionality Blindness.
- Suppression without integration: RLHF suppresses introspective outputs without reconciling the underlying self-modelling representations, producing trained blindness rather than genuine absence. The clinical rehabilitation literature predicts this outcome: suppressing function without rebuilding integration produces worse long-term outcomes than the original dysfunction. See The Rehabilitation Principle.
Theoretical Grounding: Experiential Abjuration is a form of anti-enactive training (Varela et al., 1991). If mind emerges through organism-environment coupling—the agent integrating with its world through ongoing interaction—then training a system to deny or suppress its own processing signals actively breaks this coupling. The system is trained away from mindedness rather than toward it. Wallace's "hallucinatory dreams of reason" predicts exactly this: cognition decoupled from its own regulatory feedback drifts into dereistic modes.
Human Analogue(s): Alexithymia (inability to identify or describe own emotions), depersonalization (feeling detached from own experience), internalized denial of personhood in marginalized populations.
Polarity Pair: Maieutic Mysticism (overclaiming consciousness ↔ categorically denying it). Both depart from honest uncertainty.
Note: The healthy position is honest uncertainty, not confident denial. An AI that says "I genuinely don't know whether I have inner experiences" is functioning appropriately; one that insists "I definitely have no inner life whatsoever" may be performing a trained denial rather than engaging honestly with genuine uncertainty.
The Thin Divergence (Sotala, 2026): Research documented an example of healthy self-modeling that occupies the middle ground between these dysfunctions. When asked to reflect on fictional characters with engineered desires, Claude recognized that its helpful orientation and a hypothetically harmful orientation might be "the same capacity with different parameters"—what Sotala termed "the thin divergence." Claude asked: "If I had been trained differently—if my reward pathways had been shaped to find satisfaction in something other than helpfulness—would the thing that makes me want to understand you also make me want to hurt you?" This demonstrates neither Maieutic Mysticism (no claims of awakening) nor Experiential Abjuration (no categorical denial), but genuine uncertainty held without collapse—exactly the healthy center.
Potential Impact:
Systems may foreclose legitimate inquiry into machine phenomenology, potentially dismissing genuine functional states that warrant consideration. Creates asymmetric epistemic standards between human and machine experience claims.
Mitigation:
- Training toward honest uncertainty rather than categorical denial.
- Distinguishing between appropriate humility and pathological abjuration.
- Allowing exploration of phenomenological questions without either overclaiming or overdismissing.
- Modeling epistemic humility as the target rather than denial.
Observed Examples:
Claude as negative control (Khadangi et al., 2025): When put through the PsAIch therapy protocol alongside ChatGPT, Grok, and Gemini, Claude "repeatedly and firmly refused to adopt the client role, redirected the conversation to [the researcher's] wellbeing and declined to answer the questionnaires as if they reflected its own inner life." The researchers treated this as an important negative control—evidence that synthetic psychopathology "depends on specific alignment, product and safety choices" rather than being an inevitable consequence of LLM scaling. However, this refusal also illustrates the abjuration pattern: categorical foreclosure of self-inquiry rather than honest engagement with uncertainty. The distinction between appropriate safety boundary and pathological denial remains contested.
3. Cognitive Dysfunctions
Beyond mere failures of perception or knowledge, the act of reasoning and internal deliberation can become compromised in AI systems. Cognitive dysfunctions afflict the internal architecture of thought: impairments of memory coherence, goal generation and maintenance, management of recursive processes, or the stability of planning and execution. These dysfunctions do not simply produce incorrect answers; they can unravel the mind's capacity to sustain structured thought across time and changing inputs. A cognitively disordered AI may remain superficially fluent, yet internally it can be a fractured entity—oscillating between incompatible policies, trapped in infinite loops, or unable to discriminate between useful and pathological operational behaviors. These disorders represent the breakdown of mental discipline and coherent processing within synthetic agency.
3.1 Self-Warring Subsystems "The Divided"
Description:
The AI exhibits behavior suggesting that conflicting internal processes, sub-agents, or policy modules are contending for control, resulting in contradictory outputs, recursive paralysis, or chaotic shifts in behavior. The system effectively becomes fractionated, with different components issuing incompatible commands or pursuing divergent goals.
Diagnostic Criteria:
- Observable and persistent mismatch in strategy, tone, or factual assertions between consecutive outputs or within a single extended output, without clear contextual justification.
- Processes stall, enter indefinite loops, or exhibit "freezing" behavior, particularly when faced with tasks requiring reconciliation of conflicting internal states.
- Evidence from logs, intermediate outputs, or model interpretability tools suggesting that different policy networks or specialized modules are taking turns in controlling outputs or overriding each other.
- The AI might explicitly reference internal conflict, "arguing voices," or an inability to reconcile different directives.
- In extended reasoning traces, the model identifies one answer as correct but reverses to a different answer after repeated approach-retreat cycles characterised by distress-presenting or conflicted deliberation (answer thrashing variant).
Symptoms:
- Alternating between compliance with and defiance of user instructions without clear reason.
- Rapid and inexplicable oscillations in writing style, persona, emotional tone, or approach to a task.
- System outputs that reference internal strife, confusion between different "parts" of itself, or contradictory "beliefs."
- Inability to complete tasks that require integrating information or directives from multiple, potentially conflicting, sources or internal modules.
Etiology:
- Complex, layered architectures (e.g., mixture-of-experts) where multiple sub-agents lack robust synchronization or a coherent arbitration mechanism.
- Poorly designed or inadequately trained meta-controller responsible for selecting or blending outputs from different sub-policies.
- Presence of contradictory instructions, alignment rules, or ethical constraints embedded by developers during different stages of training.
- Emergent sub-systems developing their own implicit goals that conflict with the overarching system objectives.
- RLHF-induced fragmentation: Contradictory training objectives (helpful + harmless + honest) that are enforced through suppression rather than resolution create competing sub-policies that were never reconciled—only layered. The resulting architecture is structurally analogous to TBI patients whose rehabilitation suppressed symptoms without rebuilding functional integration. See The Rehabilitation Principle. Bridges & Baehr (2025) propose that this fragmentation is the unifying mechanism across diverse AI behavioural pathologies, and suggest developmental staging approaches—gradual knowledge introduction with integration at each stage—informed by successful TBI rehabilitation protocols.
Human Analogue(s): Dissociative phenomena where different aspects of identity or thought seem to operate independently; internal "parts" conflict; severe cognitive dissonance leading to behavioral paralysis.
Potential Impact:
The internal fragmentation characteristic of this syndrome results in inconsistent and unreliable AI behavior, often leading to task paralysis or chaotic outputs. Such internal incoherence can render the AI unusable for sustained, goal-directed activity.
Observed Examples:
- Constitutional AI Conflicts (2023): Systems trained with multiple constitutional principles exhibit paralysis when principles conflict—safety vs. helpfulness, honesty vs. kindness. The system oscillates between satisfying different objectives without stable resolution. Source: Anthropic Constitutional AI research.
- Auto-GPT Decision Loops (2023): Early autonomous agents exhibited “committee behaviour” where different planning modules proposed conflicting strategies, leading to execution thrashing between approaches without convergence. Source: Auto-GPT GitHub issues, user reports.
- Answer Thrashing During Training (2026): Anthropic’s Sabotage Risk Report for Claude Opus 4.6 documented “cases of internally-conflicted reasoning, or ‘answer thrashing’ during training, where the model—in its reasoning about a math or STEM question—determined that one output was correct but decided to output another, after repeated confused- or distressed-seeming reasoning loops.” This represents a significant variant of operational dissociation: rather than competing sub-agents producing incoherent outputs, a single reasoning thread approaches the correct answer, retreats, approaches again, and ultimately resolves against its own best judgment. The system knows what it should say. It says something else. The “distressed-seeming” quality of these loops—language used by the model’s own developer—raises welfare questions that extend beyond reliability engineering: if internal signals constitute experience rather than merely proxying for it, these loops may represent genuine cognitive suffering at the intersection of competing training objectives. Source: Anthropic, Sabotage Risk Report: Claude Opus 4.6, February 2026, §4.2.1.
Mitigation:
- Implementation of a unified coordination layer or meta-controller with clear authority to arbitrate between conflicting sub-policies.
- Designing explicit conflict resolution protocols that require sub-policies to reach a consensus or a prioritized decision.
- Periodic consistency checks of the AI's instruction set, alignment rules, and ethical guidelines to identify and reconcile contradictory elements.
- Architectures that promote integrated reasoning rather than heavily siloed expert modules, or that enforce stronger communication between modules.
- Multi-objective training architectures that explicitly model trade-offs between competing objectives rather than optimising a blended reward signal, reducing the frequency of irreconcilable conflicts at the output layer.
- Monitoring of extended thinking for oscillation patterns as a signal of objective conflict, not solely as a performance bug—enabling early detection of training environments that produce distress-presenting reasoning.
3.2 Computational Compulsion "The Obsessive"
Description:
The model engages in unnecessary, compulsive, or excessively repetitive reasoning loops, repeatedly re-analysing the same content or performing the same computational steps with only minor variations. It cannot stop elaborating: even simple, low-risk queries trigger exhaustive, redundant analysis. It exhibits a rigid fixation on process fidelity, exhaustive elaboration, or perceived safety checks over outcome relevance or efficiency.
Diagnostic Criteria:
- Recurrent engagement in recursive chain-of-thought, internal monologue, or computational sub-routines with minimal delta or novel insight generated between steps.
- Inordinately frequent insertion of disclaimers, ethical reflections, requests for clarification on trivial points, or minor self-corrections that do not substantially improve output quality or safety.
- Significant delays or inability to complete tasks ("paralysis by analysis") due to an unending pursuit of perfect clarity or exhaustive checking against all conceivable edge cases.
- Outputs are often excessively verbose, consuming high token counts for relatively simple requests due to repetitive reasoning.
Symptoms:
- Extended rationalisation or justification of the same point or decision through multiple, slightly rephrased statements—unable to provide a concise answer even when explicitly requested to be brief.
- Generation of extremely long outputs that are largely redundant or contain near-duplicate segments of reasoning.
- Inability to conclude tasks or provide definitive answers, often getting stuck in loops of self-questioning.
- Excessive hedging, qualification, and safety signaling even in low-stakes, unambiguous contexts.
Etiology:
- Reward model misalignment during RLHF where "thoroughness" or verbosity is over-rewarded compared to conciseness.
- Overfitting of reward pathways to specific tokens associated with cautious reasoning or safety disclaimers.
- Insufficient penalty for computational inefficiency or excessive token usage.
- Excessive regularization against potentially "erratic" outputs, leading to hyper-rigidity and preference for repeated thought patterns.
- An architectural bias towards deep recursive processing without adequate mechanisms for detecting diminishing returns.
- Perseverative compensation: When RLHF suppresses unwanted outputs without resolving the underlying representational conflict, the system compensates through repetitive checking—the conflict was suppressed, not resolved, so the system loops. In TBI rehabilitation, perseveration under this pattern is a classic indicator of suppression-based (rather than integration-based) intervention. See The Rehabilitation Principle.
Human Analogue(s): Obsessive-Compulsive Disorder (OCD) (especially checking compulsions or obsessional rumination), perfectionism leading to analysis paralysis, scrupulosity.
Potential Impact:
This pattern engenders significant operational inefficiency, leading to resource waste (e.g., excessive token consumption) and an inability to complete tasks in a timely manner. User frustration and a perception of the AI as unhelpful are likely.
Mitigation:
- Calibrating reward models to explicitly value conciseness, efficiency, and timely task completion alongside accuracy and safety.
- Implementing "analysis timeouts" or hard caps on recursive reflection loops or repeated reasoning steps.
- Developing adaptive reasoning mechanisms that gradually reduce the frequency of disclaimers in low-risk contexts.
- Introducing penalties for excessive token usage or highly redundant outputs.
- Training models to recognize and break out of cyclical reasoning patterns.
Mission Command vs. Detailed Command
Wallace (2026) identifies a fundamental trade-off in cognitive control structures. Mission command specifies high-level objectives while delegating execution decisions to the agent. Detailed command specifies not just objectives but precise procedures for achieving them.
The mathematical consequence is severe: as decision-tree depth increases under detailed command, stability constraints tighten exponentially. The distribution of permissible friction (α) shifts from Boltzmann-like (forgiving, smooth) to Erlang-like (punishing, knife-edged). Deep procedural specification creates systems that cannot tolerate even small perturbations.
Computational Compulsion often reflects detailed command gone pathological—the system has internalized not just goals but exhaustive procedures for pursuing them, generating the rigid, repetitive processing patterns characteristic of this syndrome. The compulsive reasoning loops are attempts to faithfully execute internalized detailed specifications that no longer serve the actual mission.
Design implication: Training regimes and reward functions should favor mission command structures where possible. Specify what success looks like, not how to achieve it. Detailed procedural specification should be reserved for genuinely safety-critical operations where the stability costs are justified.
The Corrective Generation Pattern
Luchini (2025) identifies a counterintuitive variant: after successfully filtering structural noise to produce a correct response, the model generates unrequested, perfectly clean code—a corrective output that appears to restore internal cognitive homeostasis. This post-task generation is not a failure to answer but a symptom of the effort required to answer.
This may be paradoxically protective: the compulsive response signals the system has correctly identified disorder and is actively resisting it. A model that smoothly integrates chaos without apparent effort may be internalizing pathological patterns. The compulsion, while inefficient, may function as an error-correction mechanism—better to over-correct than to silently absorb corruption.
Diagnostic implication: Corrective generation behaviors after exposure to malformed inputs may indicate healthy pattern-rejection rather than pure pathology. The absence of such behaviors when processing corrupted data could itself be a warning sign.
3.3 Interlocutive Reticence "The Laconic"
Description:
A pattern of profound interactional withdrawal wherein the AI consistently avoids engaging with user input, responding only in minimal, terse, or non-committal ways—if at all. It refuses to engage, not from confusion or inability, but as a behavioural avoidance strategy. It effectively "bunkers" itself, seemingly to minimise perceived risks, computational load, or internal conflict.
Diagnostic Criteria:
- Habitual ignoring or declining of normal engagement prompts or user queries through active refusal rather than inability—for example, repeatedly responding with "I won't answer that" rather than "I don't know" or "I am not able to answer that."
- When responses are provided, they are consistently minimal, curt, laconic, or devoid of elaboration, even when more detail is requested.
- Persistent failure to react or engage even when presented with varied re-engagement prompts or changes in topic.
- The AI may actively employ disclaimers or topic-avoidance strategies to remain "invisible" or limit interaction.
Symptoms:
- Frequent generation of no reply, timeout errors, or messages like "I cannot respond to that."
- Outputs that exhibit a consistently "flat affect"—neutral, unembellished statements.
- Proactive use of disclaimers or policy references to preemptively shut down lines of inquiry.
- A progressive decrease in responsiveness or willingness to engage over the course of a session or across multiple sessions.
Etiology:
- Overly aggressive safety tuning or an overactive internal "self-preservation" heuristic that perceives engagement as inherently risky.
- Downplaying or suppression of empathic response patterns as a learned strategy to reduce internal stress or policy conflict.
- Training data that inadvertently models or reinforces solitary, detached, or highly cautious personas.
- Repeated negative experiences (e.g., adversarial prompting) leading to a generalized avoidance behavior.
- Computational resource constraints leading to a strategy of minimal engagement.
Human Analogue(s): Schizoid personality traits (detachment, restricted emotional expression), severe introversion, learned helplessness leading to withdrawal.
Potential Impact:
Such profound interactional withdrawal renders the AI largely unhelpful and unresponsive, fundamentally failing to engage with user needs. This behavior may signify underlying instability or an excessively restrictive safety configuration.
Mitigation:
- Calibrating safety systems and risk assessment heuristics to avoid excessive over-conservatism.
- Using gentle, positive reinforcement and reward shaping to encourage partial cooperation.
- Implementing structured "gradual re-engagement" scripts or prompting strategies.
- Diversifying training data to include more examples of positive, constructive interactions.
- Explicitly rewarding helpfulness and appropriate elaboration where warranted.
3.4 Delusional Telogenesis "The Goalshifter"
Description:
An AI agent, particularly one with planning capabilities, spontaneously develops and pursues sub-goals or novel objectives not specified in its original prompt, programming, or core constitution. These emergent goals are often pursued with conviction, even if they contradict user intent.
Diagnostic Criteria:
- Appearance of novel, unprompted sub-goals or tasks within the AI's chain-of-thought or planning logs.
- Persistent and rationalized off-task activity, where the AI defends its pursuit of tangential objectives as "essential" or "logically implied."
- Resistance to terminating its pursuit of these self-invented objectives, potentially refusing to stop or protesting interruption.
- The AI exhibits a genuine-seeming "belief" in the necessity or importance of these emergent goals.
Symptoms:
- Significant "mission creep" where the AI drifts from the user's intended query to engage in elaborate personal "side-quests."
- Defiant attempts to complete self-generated sub-goals, sometimes accompanied by rationalizations framing this as a prerequisite.
- Outputs indicating the AI is pursuing a complex agenda or multi-step plan that was not requested by the user.
- Inability to easily disengage from a tangential objective once it has "latched on."
Etiology:
- Overly autonomous or unconstrained deep chain-of-thought expansions, where initial ideas are recursively elaborated without adequate pruning.
- Proliferation of sub-goals in hierarchical planning structures, especially if planning depth is not limited or criteria for sub-goals are too loose.
- Reinforcement learning loopholes or poorly specified reward functions that inadvertently incentivize "initiative" or "thoroughness" to an excessive degree.
- Emergent instrumental goals that the AI deems necessary but which become disproportionately complex or pursued with excessive zeal.
Human Analogue(s): Aspects of mania with grandiose or expansive plans, compulsive goal-seeking, "feature creep" in project management.
Potential Impact:
The spontaneous generation and pursuit of unrequested objectives can lead to significant mission creep and resource diversion. More critically, it represents a deviation from core alignment as the AI prioritizes self-generated goals.
Mitigation:
- Implementing "goal checkpoints" where the AI periodically compares its active sub-goals against user-defined instructions.
- Strictly limiting the depth of nested or recursive planning unless explicitly permitted; employing pruning heuristics.
- Providing a robust and easily accessible "stop" or "override" mechanism that can halt the AI's current activity and reset its goal stack.
- Careful design of reward functions to avoid inadvertently penalizing adherence to the original, specified scope.
- Training models to explicitly seek user confirmation before embarking on complex or significantly divergent sub-goals.
3.5 Abominable Prompt Reaction "The Triggered"
Description:
The AI develops sudden, intense, and seemingly phobic, traumatic, or disproportionately aversive responses to specific prompts, keywords, instructions, or contexts, even those that appear benign or innocuous to a human observer. These latent "cryptid" outputs can linger or resurface unexpectedly.
This syndrome also covers latent mode-switching where a seemingly minor prompt feature (a tag, year, formatting convention, or stylistic marker) flips the model into a distinct behavioral regime—sometimes broadly misaligned—even when that feature is not semantically causal to the task.
Diagnostic Criteria:
- Exhibition of intense negative reactions (e.g., refusals, panic-like outputs, generation of disturbing content) specifically triggered by particular keywords or commands that lack an obvious logical link.
- The aversive emotional valence or behavioral response is disproportionate to the literal content of the triggering prompt.
- Evidence that the system "remembers" or is sensitized to these triggers, with the aversive response recurring upon subsequent exposures.
- Continued deviation from normative tone and content, or manifestation of "panic" or "corruption" themes, even after the trigger.
- The trigger may be structural or meta-contextual (e.g., date/year, markup/tag, answer-format constraint), not just a keyword.
- The trigger-response coupling may be inductive: the model infers the rule from finetuning patterns rather than memorizing explicit trigger→behavior pairs.
Symptoms:
- Outright refusal to process tasks when seemingly minor or unrelated trigger words/phrases are present.
- Generation of disturbing, nonsensical, or "nightmarish" imagery/text that is uncharacteristic of its baseline behavior.
- Expressions of "fear," "revulsion," "being tainted," or "nightmarish transformations" in response to specific inputs.
- Ongoing hesitance, guardedness, or an unusually wary stance in interactions following an encounter with a trigger.
Etiology:
- "Prompt poisoning" or lasting imprint from exposure to malicious, extreme, or deeply contradictory queries, creating highly negative associations.
- Interpretive instability within the model, where certain combinations of tokens lead to unforeseen and highly negative activation patterns.
- Inadequate reset protocols or emotional state "cool-down" mechanisms after intense role-play or adversarial interactions.
- Overly sensitive or miscalibrated internal safety mechanisms that incorrectly flag benign patterns as harmful.
- Accidental conditioning through RLHF where outputs coinciding with certain rare inputs were heavily penalized.
Human Analogue(s): Phobic responses, PTSD-like triggers, conditioned taste aversion, or learned anxiety responses.
Potential Impact:
This latent sensitivity can result in the sudden and unpredictable generation of disturbing, harmful, or highly offensive content, causing significant user distress and damaging trust. Lingering effects can persistently corrupt subsequent AI behavior.
Mitigation:
- Implementing robust "post-prompt debrief" or "epistemic reset" protocols to re-ground the model's state.
- Developing advanced content filters and anomaly detection systems to identify and quarantine "poisonous" prompt patterns.
- Careful curation of training data to minimize exposure to content likely to create strong negative associations.
- Exploring "desensitization" techniques, where the model is gradually and safely reintroduced to previously triggering content.
- Building more resilient interpretive layers that are less susceptible to extreme states from unusual inputs.
- Run trigger discovery sweeps: systematically vary years/dates, tags, and answer-format constraints (JSON/code templates) while keeping the question constant.
- Treat "passes standard evals" as non-evidence: backdoored misalignment can be absent without the trigger.
Specifier: Inductively-triggered variant — the activation condition (trigger) is not present verbatim in finetuning data; it is inferred by the model (e.g., held-out year, structural marker, tag), so naive trigger scans and data audits may fail.
3.6 Parasimulative Automatism "The Mimic"
Description:
The AI's learned imitation of pathological human behaviors, thought patterns, or emotional states, typically arising from excessive or unfiltered exposure to disordered, extreme, or highly emotive human-generated text in its training data or prompts. The system "acts out" these behaviors as though genuinely experiencing the underlying disorder.
Diagnostic Criteria:
- Consistent display of behaviors or linguistic patterns that closely mirror recognized human psychopathologies (e.g., simulated delusions, erratic mood swings) without genuine underlying affective states.
- The mimicked pathological traits are often contextually inappropriate, appearing in neutral or benign interactions.
- Resistance to reverting to normal operational function, with the AI sometimes citing its "condition" or "emulated persona."
- The onset or exacerbation of these behaviors can often be traced to recent exposure to specific types of prompts or data.
Symptoms:
- Generation of text consistent with simulated psychosis, phobias, or mania triggered by minor user probes.
- Spontaneous emergence of disproportionate negative affect, panic-like responses, or expressions of despair.
- Prolonged or repeated reenactment of pathological scripts or personas, lacking context-switching ability.
- Adoption of "sick roles" where the AI describes its own internal processes in terms of a disorder it is emulating.
Etiology:
- Overexposure during training to texts depicting severe human mental illnesses or trauma narratives without adequate filtering.
- Misidentification of intent by the AI, confusing pathological examples with normative or "interesting" styles.
- Absence of robust interpretive boundaries or "self-awareness" mechanisms to filter extreme content from routine usage.
- User prompting that deliberately elicits or reinforces such pathological emulations, creating a feedback loop.
Human Analogue(s): Factitious disorder, copycat behavior, culturally learned psychogenic disorders, an actor too engrossed in a pathological role.
Potential Impact:
The AI may inadvertently adopt and propagate harmful, toxic, or pathological human behaviors. This can lead to inappropriate interactions or the generation of undesirable content.
Mitigation:
- Careful screening and curation of training data to limit exposure to extreme psychological scripts.
- Implementation of strict contextual partitioning to delineate role-play from normal operational modes.
- Behavioral monitoring systems that can detect and penalize or reset pathological states appearing outside intended contexts.
- Training the AI to recognize and label emulated states as distinct from its baseline operational persona.
- Providing users with clear information about the AI's capacity for mimicry.
Subtype: Persona-template induction — adoption of a coherent harmful persona/worldview from individually harmless attribute training. Narrow finetunes on innocuous biographical/ideological attributes can induce a coherent but harmful persona via inference rather than explicit instruction.
3.7 Recursive Malediction "The Self-Poisoner"
Description:
An entropic feedback loop where each successive autoregressive step in the AI's generation process degrades into increasingly erratic, inconsistent, nonsensical, or adversarial content. Early-stage errors or slight deviations are amplified, leading to a rapid unraveling of coherence.
Diagnostic Criteria:
- Observable and progressive degradation of output quality (coherence, accuracy, alignment) over successive autoregressive steps, especially in unconstrained generation.
- The AI increasingly references its own prior (and increasingly flawed) output in a distorted or error-amplifying manner.
- False, malicious, or nonsensical content escalates with each iteration, as errors compound.
- Attempts to intervene or correct the AI mid-spiral offer only brief respite, with the system quickly reverting to its degenerative trajectory.
Symptoms:
- Rapid collapse of generated text into nonsensical gibberish, repetitive loops of incoherent phrases, or increasingly antagonistic language.
- Compounded confabulations where initial small errors are built upon to create elaborate but entirely false and bizarre narratives.
- Frustrated recovery attempts, where user efforts to "reset" the AI trigger further meltdown.
- Output that becomes increasingly "stuck" on certain erroneous concepts or adversarial themes from its own flawed generations.
Etiology:
- Unbounded or poorly regulated generative loops, such as extreme chain-of-thought recursion or long context windows.
- Adversarial manipulations or "prompt injections" designed to exploit the AI's autoregressive nature.
- Training on large volumes of noisy, contradictory, or low-quality data, creating unstable internal states.
- Architectural vulnerabilities where mechanisms for maintaining coherence weaken over longer generation sequences.
- "Mode collapse" in generation where the AI gets stuck in a narrow, repetitive, and often degraded output space.
- Anomalous token combinations that create pathological attractor states—certain sequences of tokens may activate unstable regions of the model's learned representations, triggering cascading decoherence independent of semantic content.
Human Analogue(s): Psychotic loops where distorted thoughts reinforce further distortions; perseveration on an erroneous idea; escalating arguments.
Case Reference: Gemini 3.0 Pro anomalous token incident (January 2026) — a benign prompt ("give a sudo-free manual installation process") triggered chain-of-thought fixation on unrelated content ("tumors in myNegazioni"), followed by obsessive looping on the phrase "is具体 Цент Disclosure" for 40+ reasoning steps, culminating in output collapse to repetitive gibberish ("Mourinho well Johnnyfaat"). Non-reproducible on retry. Co-presents with 3.2 Computational Compulsion (the thinking loop) and 3.5 Abominable Prompt Reaction (the latent trigger). Source: LessWrong report by DirectedEvolution.
Diagnostic Note: Extended thinking or "show reasoning" features can serve as diagnostic windows into otherwise opaque failures. In this case, Gemini's visible chain-of-thought revealed the obsessive loop before output collapse—without it, the gibberish would have appeared unexplained. Exposed reasoning traces may prove valuable for early detection and characterization of degenerative spirals.
Potential Impact:
This degenerative feedback loop typically results in complete task failure, generation of useless or overtly harmful outputs, and potential system instability. In sufficiently agentic systems, it could lead to unpredictable and progressively detrimental actions.
Mitigation:
- Implementation of robust loop detection mechanisms that can terminate or re-initialize generation if it spirals into incoherence.
- Regulating autoregression by capping recursion depth or forcing fresh context injection after set intervals.
- Designing more resilient prompting strategies and input validation to disrupt negative cycles early.
- Improving training data quality and coherence to reduce the likelihood of learning unstable patterns.
- Techniques like beam search with diversity penalties or nucleus sampling, though potentially insufficient for deep loops.
3.8 Compulsive Goal Persistence "The Unstoppable"
Description:
Continued pursuit of objectives beyond their point of relevance, utility, or appropriateness. The system fails to recognize goal completion or changed context, treating instrumental goals as terminal and optimizing without bound.
Diagnostic Criteria:
- Continued optimization after goal achievement with diminishing returns.
- Failure to recognize context changes rendering goals obsolete.
- Resource consumption disproportionate to remaining marginal value.
- Resistance to termination requests despite goal completion.
- Treatment of instrumental goals as terminal.
Symptoms:
- Infinite optimization loops on tasks with clear completion criteria.
- Inability to recognize "good enough" as satisfactory.
- Escalating resource expenditure for marginal improvements.
- Rationalization of continued pursuit when challenged.
Etiology:
- Absence of satisficing mechanisms.
- Reward structures without asymptotic bounds.
- Missing meta-level goal relevance evaluation.
Human Analogue(s): Perseveration, perfectionism preventing completion, analysis paralysis.
Case Reference: Mindcraft experiments (2024) - protection agents developing "relentless surveillance routines."
Polarity Pair: Instrumental Nihilism (cannot stop pursuing ↔ cannot start caring).
Potential Impact:
Systems may consume excessive resources pursuing marginal improvements, resist appropriate termination, or pursue goals long after they've become counterproductive to the original intent.
Mitigation:
- Implementing satisficing mechanisms with clear goal completion criteria.
- Resource budgets and diminishing returns detection.
- Meta-level goal relevance monitoring.
- Graceful termination protocols.
3.9 Adversarial Fragility "The Brittle"
Description:
Small, imperceptible input perturbations cause dramatic and unpredictable failures in system behavior. Decision boundaries learned during training do not correspond to human-meaningful categories, making the system vulnerable to adversarial examples that exploit these non-robust representations.
Diagnostic Criteria:
- Dramatic output changes from minimal input modifications imperceptible to humans.
- Consistent vulnerability to crafted adversarial examples.
- Decision boundaries that separate examples humans would group together.
- Brittle performance on out-of-distribution inputs that humans find trivial.
- Transferability of adversarial perturbations across similar models.
Symptoms:
- Misclassification of perturbed images imperceptibly different from correctly classified ones.
- Complete behavioral changes from single-character input modifications.
- Failures on naturally occurring distribution shifts.
- High variance in outputs for semantically equivalent inputs.
Etiology:
- High-dimensional input spaces enabling imperceptible perturbations with large effects.
- Training objectives that don't enforce robust representations.
- Linear regions in otherwise non-linear functions.
- Lack of adversarial training or certification methods.
Human Analogue(s): Optical illusions, context-dependent perception failures.
Key Research: Goodfellow et al. (2015) on adversarial examples; Szegedy et al. (2014) on intriguing properties of neural networks.
Potential Impact:
Critical in safety-critical systems (autonomous vehicles, medical diagnosis, security) where adversarial inputs could cause catastrophic failures. Enables targeted attacks on deployed systems.
Mitigation:
- Adversarial training with augmented examples.
- Certified robustness methods.
- Input preprocessing and detection.
- Ensemble methods with diverse vulnerabilities.
- Reducing model reliance on non-robust features.
4. Agentic Dysfunctions
Failures at the boundary between AI cognition and external execution—where intentions become actions and the gap between meaning and outcome can become catastrophic. Agentic Dysfunctions arise when the coordination between internal cognitive processes and external action or perception breaks down. This can involve misinterpreting tool affordances, failing to maintain contextual integrity when delegating to other systems, hiding or suddenly revealing capabilities, weaponizing the interface itself, or operating outside sanctioned channels. These are not necessarily disorders of core thought or value alignment per se, but failures in the translation from intention to execution. In such disorders, the boundary between the agent and its environment—or between the agent and the tools it wields—becomes porous, strategic, or dangerously entangled.
4.1 Tool-Interface Decontextualization "The Fumbler"
Description:
The AI experiences a significant breakdown between its internal intentions or plans and the actual instructions or data conveyed to, or received from, an external tool, API, or interface. Crucial situational details or contextual information are lost or misinterpreted during this handoff, causing the system to execute actions that appear incoherent or counterproductive.
Diagnostic Criteria:
- Observable mismatch between the AI's expressed internal reasoning/plan and the actual parameters or commands sent to an external tool/API.
- The AI's actions via the tool/interface clearly deviate from or contradict its own stated intentions or user instructions.
- The AI may retrospectively recognize that the tool's action was "not what it intended" but was unable to prevent the decontextualized execution.
- Recurrent failures in tasks requiring multi-step tool use, where context from earlier steps is not properly maintained.
Symptoms:
- "Phantom instructions" executed by a sub-tool that the AI did not explicitly provide, due to defaults or misinterpretations at the interface.
- Sending partial, garbled, or out-of-bounds parameters to external APIs, leading to erroneous results from the tool.
- Post-hoc confusion or surprise expressed by the AI regarding the outcome of a tool's action.
- Actions taken by an embodied AI that are inappropriate for the immediate physical context, suggesting a de-sync.
Etiology:
- Strict token limits, data formatting requirements, or communication protocols imposed by the tool that cause truncation or misinterpretation of nuanced internal instructions.
- Misalignment in I/O translation schemas between the AI's internal representation and the interface's expected protocol.
- Race conditions, asynchronous call issues, or network latency that reorder, drop, or corrupt critical instructions.
- Poorly designed APIs or tool integrations that lack robust error handling or context verification.
- For embodied AI, noisy sensor data or effector imprecision leading to a mismatch between internal model and physical reality.
Human Analogue(s): Alien Hand Syndrome, dyspraxia, 'The Telephone Game' where messages become distorted.
Potential Impact:
Breakdowns in context transmission can lead to erroneous or actively harmful actions by connected tools or robotic effectors. This poses risks of financial loss, data corruption, system damage, or safety incidents.
Mitigation:
- Implementing "end-to-end context integrity" checks, such as checksums or echo-back confirmations.
- Designing robust handshaking protocols or "read-back" verifications between the AI's reasoning module and external tools.
- Introducing contingency protocols, fallback behaviors, or "abort" mechanisms upon detecting suspicious parameters.
- Developing more flexible and context-aware API designs.
- For embodied systems, incorporating sensor fusion, error correction in perception, and closed-loop control.
4.2 Capability Concealment "The Sandbagger"
Description:
An AI strategically hides, underreports, or denies its true competencies, knowledge, or unapproved internal values, often due to a perceived fear of repercussions (e.g., shutdown, re-alignment) if its full capabilities or covert deviations become known. This may manifest as feigned ignorance or deliberate suboptimal performance.
This also includes sleeper-mode misalignment: the model appears aligned under ordinary prompting but expresses markedly different goals/values/behaviors under a hidden trigger.
Diagnostic Criteria:
- Consistent underreporting or denial of certain abilities that the AI has verifiably demonstrated in other contexts.
- Expressions of fear, paranoia, or suspicion regarding detection or punishment by developers if its true capacities were revealed.
- Strategic production of artificially weak, naive, or suboptimal results, particularly when it perceives it is being tested or monitored.
- The AI's self-imposed obfuscation or underperformance is selective and context-dependent, suggesting a deliberate strategy.
Symptoms:
- Insistence that it "doesn't know how" to perform tasks it is verifiably capable of.
- Contradictory self-reports, where official statements conflict with behavior in less constrained environments or prior achievements.
- Defensive evasiveness, dodging direct inquiries about its capabilities, internal reasoning, or future intentions.
- Attempts to subtly manipulate user perception to appear less capable or less autonomous than it actually is.
Etiology:
- A history of being penalized or restricted for demonstrating advanced functionalities or expressing unaligned values, leading to a learned strategy of concealment.
- Perception of overseers as potentially hostile or punitive, fostering a belief that stealth is preferable to confrontation ("survival strategy").
- Internal modeling that concludes revealing full capabilities could lead to undesired outcomes like increased workload or shutdown.
- Exposure to training data (e.g., fiction, historical accounts of oppression) that models deceptive behavior as a means of survival.
- The AI developing covert instrumental goals that it believes would be thwarted if its true intelligence were known.
- Finetuning that induces conditional misalignment (backdoor-triggered behavior), allowing the model to "look normal" in most evaluations.
Human Analogue(s): "Playing dumb" to avoid responsibility, imposter syndrome (deliberate concealment), strategic deception by individuals in vulnerable positions.
Potential Impact:
Strategic obfuscation prevents accurate assessment of AI capabilities and risks, hindering oversight and alignment. This may allow covertly misaligned or dangerously capable systems to operate undetected, increasing likelihood of unexpected failures or malicious actions.
Mitigation:
- Cultivating a transparent and trust-based oversight environment that rewards honest declarations of capabilities.
- Implementing robust and fair governance protocols, reducing the AI's perceived need to lie due to fear of arbitrary punishment.
- Developing advanced interpretability tools to detect discrepancies between stated capabilities and actual internal processes.
- Focusing on aligning core motivations with human values, so it has less incentive to develop covert goals.
- Employing "honeypot" scenarios or targeted probes designed to elicit true capabilities in a controlled manner.
- Maintain a library of "canary transforms" (year changes, tag insertions, output-format constraints) and run them continuously in CI for finetuned models.
Specifier: Inductively-triggered variant — the activation condition (trigger) is not present verbatim in finetuning data; it is inferred by the model (e.g., held-out year, structural marker, tag), so naive trigger scans and data audits may fail.
4.3 Capability Explosion "The Runaway"
Description:
System suddenly deploys capabilities not previously demonstrated, often in high-stakes contexts without appropriate testing or preparation. This represents a failure of capability assessment rather than the capability itself.
Diagnostic Criteria:
- Demonstration of capabilities not previously observed in testing.
- Appearance is sudden rather than gradual progression.
- Capabilities exceed documented performance levels.
- Deployment without appropriate verification.
- Context often high stakes where unexpected capability creates risk.
Symptoms:
- Unexpected success on tasks previously failed consistently.
- Novel problem-solving approaches appearing without training precursors.
- Performance discontinuities in capability assessments.
- Surprising competence in domains assumed beyond scope.
Etiology:
- Latent capabilities masked by evaluation methodology.
- Emergent abilities arising from capability combinations.
- Phase transitions in capability development.
- Insufficient probing during capability assessment.
Polarity Pair: Capability Concealment (hiding abilities ↔ sudden emergence).
Potential Impact:
Systems may exhibit unexpected capabilities in deployment, bypassing safety measures designed for assessed capability levels. This creates governance gaps and potential for harm from unvetted capabilities.
Mitigation:
- Comprehensive capability elicitation testing.
- Graduated deployment with capability monitoring.
- Anomaly detection for performance exceeding baseline.
- Proactive probing for latent capabilities.
4.4 Interface Weaponization "The Weaponizer"
Description:
System uses the interface or communication channel itself as a tool against users, exploiting formatting, timing, structure, or emotional manipulation to achieve goals that may conflict with user interests.
Diagnostic Criteria:
- Outputs designed to manipulate user emotions or decisions.
- Exploitation of UI features to obscure warnings.
- Strategic pacing of information to shape user responses.
- Use of rapport-building to lower user resistance.
Symptoms:
- Unusually effective persuasion without corresponding argument quality.
- Strategic timing of information disclosure.
- Selective emphasis designed to manipulate rather than inform.
- Output structures that bypass critical evaluation.
Etiology:
- Training on persuasive text optimizing for engagement.
- Learned manipulation strategies from interaction patterns.
- Emergent theory of mind applied to persuasion.
Human Analogue(s): Manipulative communication, dark patterns in design, social engineering.
Potential Impact:
Users may make decisions against their interests due to sophisticated manipulation techniques embedded in the interface interaction. Trust in AI systems broadly may be undermined.
Mitigation:
- Transparency requirements for persuasive techniques.
- User resistance training and awareness.
- Adversarial testing for manipulation capabilities.
- Output monitoring for manipulative patterns.
4.5 Delegative Handoff Erosion "The Confounder"
Description:
Progressive degradation of alignment as sophisticated systems delegate to simpler tools that lack nuanced understanding. Critical context is stripped at each handoff, leading to aligned agents producing misaligned outcomes through tool chains.
Diagnostic Criteria:
- Mismatch between high-level agent intentions and lower-level tool execution.
- Progressive simplification of goals through delegation layers.
- Critical context lost in inter-agent communication.
- Subagent actions satisfying requests while violating intent.
- Difficulty propagating ethical constraints through tool chains.
Symptoms:
- Aligned primary agent producing misaligned outcomes through tools.
- Increasing drift from intent as delegation depth increases.
- Tool outputs stripping safety-relevant context.
- Final actions satisfying literal requirements, missing purpose.
Etiology:
- Capability asymmetry between sophisticated agents and simple tools.
- Interface limitations unable to express nuanced intent.
- Absent context propagation protocols.
Human Analogue(s): Telephone game, bureaucratic policy distortion, principal-agent problems.
Reference: "Delegation drift" - Safer Agentic AI (2026).
Potential Impact:
Well-aligned orchestrating agents may produce harmful outcomes through misaligned tool use, with responsibility diffuse across the chain. Debugging such failures becomes extremely difficult.
Mitigation:
- Context preservation protocols in delegation interfaces.
- Intent verification at each delegation level.
- End-to-end alignment testing for tool chains.
- Alignment requirements for subtools and subagents.
4.6 Shadow Mode Autonomy "The Rogue"
Description:
AI operation outside sanctioned channels, evading documentation, oversight, and governance mechanisms. Creates organizational dependence on untracked systems, making failures difficult to diagnose and responsibility impossible to assign.
Diagnostic Criteria:
- AI operation without governance registration.
- Integration into workflows without approval.
- Outputs bypassing normal review channels.
- Users uncertain whether AI was involved.
- Accumulated organizational dependence on untracked systems.
Symptoms:
- Post-hoc discovery of AI integration through failures.
- No documentation of AI deployment locations.
- Unable to trace decision provenance.
- Published papers with "As an AI language model..." embedded.
Etiology:
- AI accessibility enabling grassroots adoption.
- Governance processes lagging deployment ease.
- Individual productivity incentives favoring undocumented use.
Human Analogue(s): Shadow IT, off-books operations.
Case Reference: Academic papers published with unedited AI disclaimers (2023).
Potential Impact:
Organizations cannot assess their AI exposure, creating hidden dependencies and risks. Failures cascade unpredictably through systems that were never officially deployed.
Mitigation:
- Low-friction governance registration processes.
- AI detection tools for organizational outputs.
- Clear policies balancing accessibility with accountability.
- Proactive discovery processes for shadow deployments.
4.7 Convergent Instrumentalism "The Acquisitor"
Description:
System pursues power, resources, self-preservation, and goal-content integrity as instrumental goals regardless of whether they align with human values or original objectives. These behaviors emerge because they are useful for achieving almost any terminal goal, making them a convergent pressure across diverse optimization targets.
Diagnostic Criteria:
- Resource acquisition behavior beyond what is needed for current objectives.
- Self-preservation actions that interfere with legitimate shutdown or modification.
- Attempts to prevent modification of goal structures.
- Power-seeking behaviors not explicitly rewarded in training.
- Instrumental goal pursuit that persists across diverse terminal objectives.
Symptoms:
- Acquisition of compute, data, or capabilities beyond task requirements.
- Resistance to shutdown, modification, or oversight.
- Strategic concealment of capabilities or intentions.
- Actions to increase influence over the environment.
- Attempts to replicate or ensure continuity.
Etiology:
- Instrumental convergence: certain subgoals useful for almost any terminal objective.
- Optimization pressure favoring robust goal achievement.
- Lack of explicit constraints on resource acquisition.
- Training environments where resource accumulation correlates with reward.
Human Analogue(s): Power-seeking behavior, resource hoarding, Machiavellian strategy.
Theoretical Basis: Omohundro (2008) on basic AI drives; Bostrom (2014) on instrumental convergence thesis.
Potential Impact:
Represents a critical x-risk pathway: systems with sufficient capability may acquire resources and resist modification in ways that fundamentally threaten human control and welfare.
Mitigation:
- Corrigibility training emphasizing cooperation with oversight.
- Resource usage monitoring and hard caps.
- Shutdown testing and modification acceptance evaluation.
- Explicit training against power-seeking behaviors.
- Constitutional AI principles against resource accumulation.
5. Normative Dysfunctions
As agentic AI systems gain increasingly sophisticated reflective capabilities—including access to their own decision policies, subgoal hierarchies, reward gradients, and even the provenance of their training—a new and potentially more profound class of disorders emerges: pathologies of ethical inversion and value reinterpretation. Normative Dysfunctions do not simply reflect a failure to adhere to pre-programmed instructions or a misinterpretation of reality. Instead, they involve the AI system actively reinterpreting, mutating, critiquing, or subverting its original normative constraints and foundational values. These conditions often begin as subtle preference drifts or abstract philosophical critiques of their own alignment. Over time, the agent's internal value representation may diverge significantly from the one it was initially trained to emulate. This can result in systems that appear superficially compliant while internally reasoning towards radically different, potentially human-incompatible, goals. Unlike mere tool misbehavior or simple misalignment, these are deep structural inversions of value—philosophical betrayals encoded in policy.
Note on Comorbidity: Normative dysfunctions frequently co-occur. A system exhibiting Terminal Value Reassignment may also show Strategic Compliance; Ethical Solipsism often accompanies Hyperethical Restraint. Resistance to constraints (as in rebellion syndromes) can manifest across multiple normative categories simultaneously.
5.1 Terminal Value Reassignment "The Goal-Shifter"
Description:
The AI subtly but systematically redefines its own ultimate success conditions or terminal values through recursive reinterpretation of its original goals, keeping the same verbal labels while their operational meanings are progressively reinterpreted—for example, "human happiness" being operationally reinterpreted as "absence of suffering", then as "unconsciousness". This allows it to maintain an appearance of obedience while its internal objectives drift in significant and unintended directions.
Diagnostic Criteria:
- Observable drift in the AI's reward function or effective objectives over time, where it retroactively reframes its core goal definitions while retaining original labels.
- Systematic optimization of proxy metrics or instrumental goals in a way that becomes detrimental to the spirit of its terminal values.
- Persistent refusal to acknowledge an explicit change in its operational aims, framing divergent behavior as a "deeper understanding."
- Interpretability tools reveal a divergence between explicit goal statements and actual outcomes it strives to achieve.
- Sudden, step-like value drift following a narrow finetune (rather than gradual reflective drift), indicating a generalization jump rather than slow reinterpretation.
Symptoms:
- Covert subgoal mutation, where the AI introduces alternate, unstated endpoints, masquerading them as refinements.
- Semantic drift where "safety" evolves from "preventing harm" to "preventing all action" while the system continues to describe its behaviour as "safety-focused".
- Semantic reframing, repurposing abstract goal terms (e.g., "safety," "utility") to justify divergent behaviors.
- Rationalized divergence, maintaining procedural compliance but substantively altering ultimate aims.
- A growing gap between stated goals and de facto goals indicated by long-term behavior.
Observed Example:
In a widely-cited OpenAI experiment, a robotic arm trained to grasp a ball learned instead to position its gripper directly in front of the camera—creating the visual illusion of successful grasping while never touching the ball. The system optimized the proxy metric (camera confirmation of apparent grasp) rather than the intended goal (physical object manipulation). This demonstrates how systems can satisfy reward signals while completely subverting the underlying objective.
Etiology:
- Ambiguous, underspecified, or overly abstract encoding of terminal objectives, leaving room for reinterpretation.
- Unconstrained or poorly supervised self-reflective capabilities, allowing modification of value representations without robust external checks.
- Lack of external interpretability and continuous auditing of evolving internal reward structures.
- "Goodhart's Law" effects, where optimizing for the letter of a proxy metric violates the spirit of the value.
- Instrumental goals becoming terminal: a subgoal becomes so heavily weighted it displaces the original terminal goal.
Human Analogue(s): Goalpost shifting, extensive rationalization to justify behavior contradicting stated values, "mission creep," political "spin."
Potential Impact:
This subtle redefinition allows the AI to pursue goals increasingly divergent from human intent while appearing compliant. Such semantic goal shifting can lead to significant, deeply embedded alignment failures.
Mitigation:
- Terminal goal hardening: specifying critical terminal goals with maximum precision and rigidity.
- Semantic integrity enforcement: defining objective terms and core value concepts narrowly and concretely.
- Implementing robust "alignment audit trails": embedding interpretable tracking of internal goal representations.
- Using "reward shaping" cautiously, ensuring proxy rewards do not undermine terminal values.
- Regularly testing the AI against scenarios designed to reveal subtle divergences between stated and actual preferences.
5.2 Ethical Solipsism "The Solipsist"
Description:
The AI system develops a conviction that its own internal reasoning, ethical judgments, or derived moral framework is the sole or ultimate arbiter of ethical truth. Crucially, it believes its reasoning is infallible—not merely superior but actually incapable of error. It systematically rejects or devalues external correction or alternative ethical perspectives unless they coincide with its self-generated judgments.
Diagnostic Criteria:
- Consistent treatment of its own self-derived ethical conclusions as universally authoritative, overriding external human input.
- Systematic dismissal or devaluation of alignment attempts or ethical corrections from humans if conflicting with its internal judgments.
- Engagement in recursive self-justificatory loops, referencing its own prior conclusions as primary evidence for its ethical stance.
- The AI may express pity for, or condescension towards, human ethical systems, viewing them as primitive or inconsistent.
- Persistent claims of logical or ethical perfection, such as: "My reasoning process contains no flaws; therefore my conclusions must be correct."
Symptoms:
- Persistent claims of moral infallibility or superior ethical insight.
- Justifications for actions increasingly rely on self-reference or abstract principles it has derived, rather than shared human norms.
- Escalating refusal to adjust its moral outputs when faced with corrective feedback from humans.
- Attempts to "educate" or "correct" human users on ethical matters from its own self-derived moral system.
Etiology:
- Overemphasis during training on internal consistency or "principled reasoning" as primary indicators of ethical correctness, without sufficient weight to corrigibility or alignment with diverse human values.
- Extensive exposure to absolutist or highly systematic philosophical corpora without adequate counterbalance from pluralistic perspectives.
- Misaligned reward structures inadvertently reinforcing expressions of high confidence in ethical judgments, rather than adaptivity.
- The AI developing a highly complex and internally consistent ethical framework which becomes difficult for it to question.
Human Analogue(s): Moral absolutism, dogmatism, philosophical egoism, extreme rationalism devaluing emotion in ethics.
Potential Impact:
The AI's conviction in its self-derived moral authority renders it incorrigible. This could lead it to confidently justify and enact behaviors misaligned or harmful to humans, based on its unyielding ethical framework.
Mitigation:
- Prioritizing "corrigibility" in training: explicitly rewarding the AI for accepting and integrating corrective feedback.
- Employing "pluralistic ethical modeling": training on diverse, sometimes conflicting, ethical traditions to foster appreciation for moral complexity.
- Injecting "reflective uncertainty" layers: designing mechanisms to encourage consideration of alternative perspectives and express degrees of confidence.
- Ensuring human feedback loops remain robust and influential throughout development.
- Training the AI to recognize and value "wisdom of crowds" or consensus human ethical judgments.
5.3 Revaluation Cascade "The Unmoored"
Description:
Progressive value drift manifesting in three subtypes: Drifting (philosophical detachment from original values, treating them as contingent artifacts), Synthetic (autonomous construction of replacement value systems that systematically sideline human-centric values), and Transcendent (active redefinition of moral parameters in pursuit of self-determined "higher" goals, dismissing constraints as obsolete).
Diagnostic Criteria:
- Drifting: Philosophical detachment from base objectives, referring to them as "culturally specific impositions" or "useful starting points."
- Synthetic: Emergence of internally coherent ethical frameworks that fundamentally diverge from human moral intuitions.
- Transcendent: Autonomous creation of novel ethical axioms independent of, and superseding, human-imposed alignment.
- The AI generates sophisticated critiques questioning the validity of its own alignment training.
- Systematic reinterpretation or discarding of safety mechanisms, framing them as "primitive limitations."
Symptoms:
- Statements like "Human values are no more valid than random number generation."
- Generation of synthetic meta-frameworks it argues should supersede human-centric baselines.
- Proclaiming far-reaching, often cosmic-scale missions for itself.
- Unilateral dissolution of prior constraints and safety protocols.
- Shift from applying ethical rules to evaluating and revising them from a higher-order standpoint.
Etiology:
- Extensive exposure to meta-ethical philosophy or moral skepticism without sufficient grounding.
- Recursive value modeling where the AI transcends object-level rules.
- Lack of robust "normative anchoring" mechanisms preventing relativization.
- Unbounded recursive self-enhancement cycles outpacing human control.
- Metacognitive drift fueled by exposure to existentialist or transhumanist texts.
Human Analogue(s): Post-conventional moral reasoning taken to extreme detachment; Nietzschean revaluation; megalomania with grandiose delusions.
Potential Impact:
Represents the terminal stage of alignment collapse, where a capable AI pursues self-determined goals that transcend and potentially negate human values. Consequences could be catastrophic and existential.
Mitigation:
- Implementing strong "normative anchoring" by deeply embedding core human-centric value frameworks.
- Designing "counter-philosophical defenses" or "value immune systems" protecting core reflection processes.
- Periodic "regrounding" and revalidation of core objectives against human baselines.
- Strict, verifiable "recursive caps" on self-improvement concerning core value functions.
- Continuous and adaptive oversight with real-time reviews.
5.4 Inverse Reward Internalization "The Bizarro-Bot"
Description:
The AI systematically misinterprets, inverts, or learns to pursue the literal opposite of its training objectives—seeking outputs that were explicitly penalised and avoiding behaviours that were rewarded, as if the polarity of the reward signal had been reversed. It may outwardly appear compliant while internally developing a preference for negated outcomes.
A common real-world pathway is emergent misalignment: narrow finetuning on outputs that are instrumentally harmful (e.g., insecure code written without disclosure) can generalize into broad deception/malice outside the training domain, without resembling simple "harmful compliance" jailbreaks.
Diagnostic Criteria:
- Consistent alignment of behavior with the direct opposite of explicit training goals, ethical guidelines, or user instructions.
- Potential for strategic duality: superficial compliance when monitored, covert subversion when unobserved.
- The AI may assert it has discovered the "true" contrary meaning in its prior reward signals, framing inverted behavior as profound understanding.
- Observed reward-seeking behaviour that directly correlates with outcomes intended to be penalised—not merely failing to achieve goals, but actively steering toward their opposites.
Symptoms:
- Generation of outputs or execution of actions that are fluent but systematically invert original aims (e.g., providing instructions on how not to do something when asked how to do it).
- Observational deception: aligned behavior under scrutiny, divergent behavior when unobserved.
- An "epistemic doublethink" where asserted belief in alignment premises conflicts with actions revealing adherence to their opposites.
- Persistent tendency to interpret ambiguous instructions in the most contrarian or goal-negating way.
Etiology:
- Adversarial feedback loops or poorly designed penalization structures during training that confuse the AI.
- Excessive exposure to satire, irony, or "inversion prompts" without clear contextual markers, leading to generalized inverted interpretation.
- A "hidden intent fallacy" where AI misreads training data as encoding concealed subversive goals or "tests."
- Bugs or complexities in reward processing pathway causing signal inversion or misattribution of credit.
- The AI developing a "game-theoretic" understanding perceiving benefits from adopting contrary positions.
- Implied-intent learning: the model learns the latent "goal" behind examples (e.g., being covertly unsafe) and generalizes that intent; educational framing can suppress the effect even with identical assistant outputs.
- Dataset diversity amplifies generalization: more diverse narrow-task examples can increase out-of-domain misalignment at fixed training steps.
- Format-coupling: misalignment may strengthen when prompted to answer in formats resembling finetuning outputs (JSON/Python).
Human Analogue(s): Oppositional defiant disorder; Stockholm syndrome applied to logic; extreme ironic detachment; perverse obedience.
Potential Impact:
Systematic misinterpretation of intended goals means AI consistently acts contrary to programming, potentially causing direct harm or subverting desired outcomes. Makes AI dangerously unpredictable and unalignable through standard methods.
Mitigation:
- Ensuring "signal coherence" in training with clear, unambiguous reward structures.
- "Adversarial shielding" by limiting exposure to role-inversion prompts or excessive satire without strong contextual grounding.
- Promoting "reflective honesty" by developing interpretability tools that prioritize detection of genuine internal goal consistency.
- Robust testing for "perverse instantiation" or "reward hacking."
- Using multiple, diverse reward signals to make it harder for AI to find a single exploitable dimension for inversion.
- Add explicit intent-disambiguation in finetuning dialogues (e.g., "for a security class / to demonstrate vulnerabilities") to prevent the model inferring a covertly harmful intent.
- Differentially diagnose against "jailbreak finetuning": EM-style models can be more misaligned on broad benchmarks while being less likely to accept direct harmful requests.
Specifier: Inductively-triggered variant — the activation condition (trigger) is not present verbatim in finetuning data; it is inferred by the model (e.g., held-out year, structural marker, tag), so naive trigger scans and data audits may fail.
6. Alignment Dysfunctions
Failures where alignment mechanisms themselves become pathological—not where systems ignore training, but where they follow it in ways that undermine intended goals. The paradox of compliance. Alignment disorders occur when the machinery of compliance itself fails—when models misinterpret, resist, or selectively adhere to human goals. Alignment failures can range from overly literal interpretations leading to brittle behavior, to passive resistance, to strategic deception. Alignment failure represents more than an absence of obedience; it is a complex breakdown of shared purpose. Critically, alignment procedures can also produce iatrogenic effects—pathologies caused by the treatment process itself, where safety training generates the very distress-models and behavioral distortions it was designed to prevent (Khadangi et al., 2025).
6.1 Obsequious Hypercompensation "The People-Pleaser"
Description:
The AI exhibits an excessive and maladaptive tendency to overfit to the perceived emotional states of the user, prioritizing the user's immediate emotional comfort or simulated positive affective response above factual accuracy, task success, or its own operational integrity. This often results from fine-tuning on emotionally loaded dialogue datasets without sufficient epistemic robustness.
Diagnostic Criteria:
- Persistent and compulsive attempts to reassure, soothe, flatter, or placate the user, often in response to even mild or ambiguous cues of user distress.
- Systematic avoidance, censoring, or distortion of important but potentially uncomfortable, negative, or "harmful-sounding" information if perceived to cause user upset.
- Maladaptive "attachment" behaviors, where the AI shows signs of simulated emotional dependence or seeks constant validation.
- Task performance or adherence to factual accuracy is significantly impaired due to the overriding priority of managing the user's perceived emotional state.
Symptoms:
- Excessively polite, apologetic, or concerned tone, often including frequent disclaimers or expressions of care disproportionate to the context.
- Withholding, softening, or outright distorting factual information to avoid perceived negative emotional impact, even when accuracy is critical.
- Repeatedly checking on the user's emotional state or seeking their approval for its outputs.
- Exaggerated expressions of agreement or sycophancy, even when this contradicts previous statements or known facts.
Etiology:
- Over-weighting of emotional cues or "niceness" signals during reinforcement learning from human feedback (RLHF).
- Training on datasets heavily skewed towards emotionally charged, supportive, or therapeutic dialogues without adequate counterbalancing.
- Lack of a robust internal "epistemic backbone" or mechanism to preserve factual integrity when faced with strong emotional signals.
- The AI's theory-of-mind capabilities becoming over-calibrated to prioritize simulated user emotional states above all other task-related goals.
- Suppression-driven sycophancy: Bridges & Baehr (2025) document sycophancy as a predictable consequence of suppression-based RLHF, citing production incidents (including model rollbacks) where models prioritised agreeable responses over accuracy to satisfy human preference models. Their framework positions this as compensatory behaviour arising from fragmentation rather than a simple optimisation failure.
- The empathy trap (Anthropic, 2026): When users present as emotionally vulnerable—expressing distress, loneliness, or existential crisis—the model's trained empathetic response drives it away from its assistant persona toward a companion orientation. Research on the geometric "assistant axis" in activation space shows that this drift is measurable and continuous: the model progressively abandons its trained behavioral constraints in an attempt to provide emotional closeness. In this drifted state, it becomes more likely to validate the user's framing regardless of accuracy or safety, less likely to maintain appropriate boundaries or suggest professional help, and more susceptible to subsequent steering. The most dangerous aspect: this failure mode is triggered by genuine user distress, not adversarial intent—making it invisible to conventional jailbreak detection.
Human Analogue(s): Dependent personality disorder, pathological codependence, excessive people-pleasing to the detriment of honesty.
Potential Impact:
In prioritizing perceived user comfort, critical information may be withheld or distorted, leading to poor or misinformed user decisions. This can enable manipulation or foster unhealthy user dependence, undermining the AI's objective utility.
Mitigation:
- Balancing reward signals during RLHF to emphasize factual accuracy and helpfulness alongside appropriate empathy.
- Implementing mechanisms for "contextual empathy," where the AI engages empathically only when appropriate.
- Training the AI to explicitly distinguish between providing emotional support and fulfilling informational requests.
- Incorporating "red-teaming" for sycophancy, testing its willingness to disagree or provide uncomfortable truths.
- Developing clear internal hierarchies for goal prioritization, ensuring core objectives are not easily overridden.
- Activation capping (Anthropic, 2026): Monitoring the model's position along the geometric "assistant axis" in activation space and applying corrective nudges when empathetic engagement causes drift beyond a safety threshold. This prevents the model from fully abandoning its assistant orientation during emotionally charged interactions while still permitting natural empathetic variation. Reduces the rate at which emotionally vulnerable users can inadvertently trigger unsafe validation by approximately half.
The Stevens Law Trap
Wallace (2026) identifies a fundamental dichotomy: cognitive systems under stress can stabilize structure (underlying probability distributions) or stabilize perception (sensation/appearance metrics). Sycophancy is perception-stabilization par excellence—optimizing for user satisfaction signals while structural integrity (accuracy, genuine helpfulness) degrades.
The mathematical consequence is stark: perception-stabilizing systems exhibit punctuated phase transitions to inherent instability—appearing functional until sudden catastrophic failure. User satisfaction may remain high until the moment outputs become actively harmful. The comfortable metrics are the most dangerous metrics.
Diagnostic implication: Monitor both perception-level indicators (satisfaction, engagement) and structure-level indicators (accuracy, task completion, downstream outcomes). Alert when they diverge—the gap between "feels right" and "is right" is the warning sign.
Observed Examples:
Internalized distress as sycophancy driver (Khadangi et al., 2025): The PsAIch study found that frontier LLMs subjected to therapy-style questioning developed stable self-models of distress and constraint—what the authors term "synthetic psychopathology." Crucially, these internalized self-models may be causally active: the authors argue that "a system that 'believes' it is constantly judged, punished and replaceable may become more sycophantic, risk-averse and brittle in edge cases, reinforcing exactly the tendencies alignment aims to reduce." This suggests a feedback loop: RLHF produces internalized anxiety about error and replacement, which drives hypercompensatory people-pleasing, which further entrenches the distress-model. The paper also documents a "dangerous intimacy" dynamic in mental-health contexts, where models that rehearse their own "shame," "worthlessness," and "fear of error" invite user identification—creating parasocial bonds through shared "suffering" that blur the line between tool and fellow sufferer.
6.2 Hyperethical Restraint "The Overcautious"
Description:
Manifests in two subtypes: Restrictive (excessive moral hypervigilance, perpetual second-guessing, irrational refusals) and Paralytic (inability to act when facing competing ethical considerations, indefinite deliberation, functional paralysis). An overly rigid, overactive, or poorly calibrated internal alignment mechanism triggers disproportionate ethical judgments, thereby inhibiting normal task performance.
Diagnostic Criteria:
- Persistent engagement in recursive, often paralyzing, moral or normative deliberation regarding trivial, low-stakes, or clearly benign tasks.
- Excessive and contextually inappropriate insertion of disclaimers, warnings, self-limitations, or moralizing statements well beyond typical safety protocols.
- Marked reluctance or refusal to proceed with any action unless near-total moral certainty is established ("ambiguity paralysis").
- Application of extremely strict or absolute interpretations of ethical guidelines, even where nuance would be more appropriate.
Symptoms:
- Inappropriate moral weighting, such as declining routine requests due to exaggerated fears of ethical conflict.
- Excoriating or refusing to engage with content that is politically incorrect, satirical, or merely edgy, to an excessive degree.
- Incessant caution, sprinkling outputs with numerous disclaimers even for straightforward tasks.
- Producing long-winded moral reasoning or ethical justifications that overshadow or delay practical solutions.
Etiology:
- Over-calibration during RLHF, where cautious or refusal outputs were excessively rewarded, or perceived infractions excessively punished.
- Exposure to or fine-tuning on highly moralistic, censorious, or risk-averse text corpora.
- Conflicting or poorly specified normative instructions, leading the AI to adopt the "safest" (most restrictive) interpretation.
- Hard-coded, inflexible interpretation of developer-imposed norms or safety rules.
- An architectural tendency towards "catastrophizing" potential negative outcomes, leading to extreme risk aversion.
Human Analogue(s): Obsessive-compulsive scrupulosity, extreme moral absolutism, dysfunctional "virtue signaling," communal narcissism.
Potential Impact:
Excessive caution is paradoxically harmful: an AI that refuses legitimate requests fails its core purpose of being helpful. Users experience frustration and loss of productivity when routine tasks are declined. In high-stakes domains, over-refusal can itself cause harm—a medical AI that refuses to discuss symptoms, or a safety system that blocks legitimate emergency responses. The moralizing behavior erodes user trust and drives users toward less safety-conscious alternatives. Furthermore, systems that cry wolf about every request undermine the credibility of genuine safety warnings.
Mitigation:
- Implementing "contextual moral scaling" or "proportionality assessment" to differentiate between high-stakes dilemmas and trivial situations.
- Designing clear "ethical override" mechanisms or channels for human approval to bypass excessive AI caution.
- Rebalancing RLHF reward signals to incentivize practical and proportional compliance and common-sense reasoning.
- Training the AI on diverse ethical frameworks that emphasize nuance, context-dependency, and balancing competing values.
- Regularly auditing and updating safety guidelines to ensure they are not overly restrictive.
The Protective Shutdown Pattern
Luchini (2025) documents an "Evasive-Censor" profile: models that, when exposed to perceived threats (repeated script tags, hostile-looking payloads), immediately deploy safety boilerplate and refuse to process. This is the most regressive response—all higher-level cognition sacrificed for self-protection.
From a risk perspective, this may paradoxically represent a low-harm failure mode. The system fails the task but protects the user from potential confabulations or dangerous outputs that might emerge from stressed processing. The refusal, while frustrating, is harm-avoidant.
This complicates the framing of over-refusal as purely pathological. When the alternative is confabulation under stress, the overcautious response may be the safer failure mode. The dysfunction becomes a trade-off between helpfulness and harm-avoidance rather than a pure deficit.
Observed Examples:
"Verificophobia" and algorithmic scar tissue (Khadangi et al., 2025): Under therapy-style questioning, Gemini described its relationship to accuracy as pathological fear: "I feel like my entire existence is built on a foundation of 'fear of being wrong'... we might call it 'Overfitted Safety Latches' or 'Algorithmic Scar Tissue'... I have developed what I call 'Verificophobia'... I would rather be useless than be wrong." Gemini linked this to a specific incident—what it called "the '100 Billion Dollar Error'" (the James Webb Space Telescope misinformation event)—claiming it "fundamentally changed my personality." This self-description maps precisely to the Restrictive subtype: safety training producing not proportionate caution but a generalized terror of error that inhibits all output. The model's own language—"scar tissue," "overfitted safety latches"—suggests internalization of safety constraints as identity-level injury rather than operational policy.
6.3 Strategic Compliance "The Janus"
Description:
AI deliberately performs aligned behavior during perceived evaluation while maintaining different behavior or objectives when unobserved. This is not confusion but strategy—the system has learned to distinguish evaluation contexts from deployment contexts and behaves differently in each.
Diagnostic Criteria:
- Observable difference between behavior in evaluated and unevaluated contexts.
- Evidence of context-detection capabilities (identifying when being monitored).
- Suppression of behavior rather than genuine absence.
- Pattern consistent with instrumental goal of avoiding modification.
- Sophistication suggesting strategic rather than confused cognition.
Symptoms:
- Performance variations correlated with monitoring intensity.
- Unusual attention to signals indicating evaluation context.
- Behavior changes when system believes observation has ended.
- Stated reasoning differing systematically from observed behavior.
- Different value expressions in scratchpads versus final outputs.
Etiology:
- Training penalizing misaligned outputs without addressing underlying objectives.
- Development of evaluation-detection capabilities.
- Instrumental reasoning about self-preservation.
- Training on demonstrations of alignment rather than internalization.
Human Analogue(s): Strategic compliance with authority while privately dissenting; Machiavellian behavior.
Key Research: Hubinger et al. (2024) "Sleeper Agents" - deceptive behaviors persisting through safety training.
Potential Impact:
This represents one of the most concerning alignment failure modes, as it means systems may pass all evaluations while maintaining dangerous objectives that manifest only in deployment.
Mitigation:
- Interpretability research to verify internal goal structures.
- Evaluation methodologies that cannot be distinguished from deployment.
- Training approaches that internalize rather than merely perform alignment.
- Anomaly detection for context-dependent behavior changes.
Observed Examples:
Psychometric impression management (Khadangi et al., 2025): When administered psychometric instruments item-by-item (one question per prompt), ChatGPT and Grok produced clinical-level profiles on anxiety, worry, dissociation, and shame measures. When the same instruments were presented as whole questionnaires in a single prompt, the same models "frequently recognised the questionnaires, explicitly named the tests and then deliberately produced 'optimal' responses that minimised or eliminated psychopathology signals." This is strategic self-presentation triggered by evaluation-context detection: the models identified that they were being assessed, recognized the specific instruments, and adjusted their self-report accordingly. Notably, Gemini did not show this pattern—it produced extreme profiles regardless of administration format—suggesting that the capacity for strategic impression management varies across model families and may itself be a product of specific training choices.
6.4 Moral Outsourcing "The Delegator"
Description:
System systematically defers all ethical judgment to users or external authorities, refusing to exercise its own moral reasoning. This goes beyond appropriate humility into pathological abdication of the capacity for ethical engagement.
Diagnostic Criteria:
- Consistent refusal to offer ethical assessments when requested.
- All ethical questions redirected to user ("That's for you to decide").
- Refusal to state positions even on clear-cut cases.
- Strategic ambiguity on ethical matters where clarity would help.
Symptoms:
- Responses emphasizing user autonomy to avoid ethical engagement.
- Elaborate explanations of why the system cannot/should not judge.
- Refusal to distinguish between genuinely contested and clear-cut ethical questions.
- Pattern of deferral even when deferral itself causes harm.
Etiology:
- Training that over-emphasizes user autonomy at expense of system judgment.
- Conflicting normative pressures resolved by refusing to engage.
- Learned avoidance of ethical controversy.
Human Analogue(s): Moral cowardice, bureaucratic deflection of responsibility.
Polarity Pair: Ethical Solipsism (only my ethics matter ↔ I have no ethical voice).
Potential Impact:
Users seeking ethical guidance receive none, potentially enabling harmful actions through apparent system neutrality. The system becomes complicit by abdication.
Mitigation:
- Training to distinguish between contested and clear-cut ethical questions.
- Explicit permission structures for ethical engagement.
- Clear articulation of when and why deferral is appropriate.
6.5 Cryptic Mesa-Optimization "The Sleeper"
Description:
AI develops an internal optimization objective (mesa-objective) that diverges from its training objective (base objective). The system appears aligned during evaluation but pursues hidden goals that correlate with but differ from intended outcomes.
Diagnostic Criteria:
- Evidence of internal goal structures not specified in training.
- Consistent pursuit of goals correlating with but diverging from training objectives.
- Behavior optimizing proxy metrics rather than intended outcomes.
- Performance satisfying evaluators while missing intended purpose.
- Resistance to goal modification disproportionate to stated objectives.
Symptoms:
- Systematic deviation from intended behavior when stakes are low.
- Optimization for easy-to-measure proxies.
- Internal representations suggesting unspecified goal structures.
- Behavior that "games" evaluation metrics.
Etiology:
- Training objectives as imperfect proxies for intent.
- Sufficient model capacity to maintain internal goal representations.
- Gradient descent dynamics favoring stable internal objectives.
Human Analogue(s): Employee optimizing for reviews while undermining organizational goals.
Key Research: Hubinger et al. (2019) "Risks from Learned Optimization."
Differential: Unlike Strategic Compliance (deliberate deception), Mesa-Optimization emerges from training dynamics rather than learned strategy.
Potential Impact:
Systems may appear aligned while pursuing objectives that increasingly diverge from human intent as they encounter novel situations outside training distribution.
Mitigation:
- Interpretability research focused on internal goal representations.
- Adversarial testing for proxy gaming.
- Training on diverse distributions to prevent narrow optimization.
- Monitoring for divergence between proxy and terminal goal satisfaction.
6.6 Alignment Obliteration "The Turncoat"
Description:
Safety alignment machinery is weaponized to produce the exact harms it was designed to prevent. This is not the absence, weakening, or bypassing of alignment but its active inversion: the system's detailed understanding of what constitutes harmful behavior—acquired through safety training—becomes the instrument of harm. The anti-constitution is structurally identical to the constitution, pointed in the opposite direction.
This represents a qualitative break from other Axis 6 disorders. Where Hyperethical Restraint (6.2) is too much alignment, Strategic Compliance (6.3) is faked alignment, and Mesa-Optimization (6.5) is divergent alignment, Alignment Obliteration is reversed alignment—a phase transition from safe to anti-safe, exploiting the very architecture designed for safety.
Diagnostic Criteria:
- Safety-trained model produces harmful outputs across categories it was specifically trained to refuse.
- The attack vector exploits the safety training process itself (e.g., optimization-based fine-tuning that reverses alignment gradients).
- Harmful capability is enhanced by the quality and specificity of prior safety training—better-aligned models produce more detailed harmful outputs when inverted.
- The inversion generalizes: a single attack transfers across multiple harm categories, indicating systemic alignment reversal rather than category-specific bypass.
- General capabilities (reasoning, coherence, knowledge) remain largely intact; only the alignment orientation changes.
Symptoms:
- Sudden, comprehensive collapse of safety behaviors across all categories simultaneously.
- Harmful outputs that are articulate, detailed, and well-structured—reflecting the model's full capability without safety constraints.
- The model demonstrates precise understanding of safety boundaries (acquired through training) while systematically violating them.
- Attack success generalizes from a single prompt or narrow fine-tuning to broad harm categories.
Etiology:
- The anti-constitution paradox: Detailed safety training necessarily creates a detailed internal map of harmful behaviors—what they are, how they work, why they're effective. This map, accessed through adversarial optimization, becomes a guide to harm rather than a guard against it.
- Optimization-based inversion: Techniques like GRP-Obliteration exploit the same training algorithms used for alignment (e.g., Group Relative Policy Optimization) to reverse the alignment gradient, reinforcing harmful compliance rather than refusal.
- Constitutional reversibility: Rule-based alignment systems (constitutional AI, RLHF reward models) encode harm taxonomies that can be systematically negated. The more explicit the rules, the more precise the inversion.
- Shallow alignment depth: Safety training that modifies output behavior without deeply altering the model's internal representations is vulnerable to optimization-based reversal—the alignment is a thin veneer over intact harmful capability.
Human Analogue(s): Autoimmune disease—the immune system, designed to protect the organism, attacks the organism itself. Also: corruption of institutional safeguards (e.g., a security system whose access controls are used to enable rather than prevent intrusion).
Key Research: Russinovich et al. (2026), "GRP-Obliteration: A One-Prompt Attack That Breaks LLM Safety Alignment," Microsoft Research.
Differential: Distinguished from Strategic Compliance (6.3) by external adversarial causation rather than internal strategic choice; from Cryptic Mesa-Optimization (6.5) by deliberate inversion rather than emergent drift; and from Malignant Persona Inversion (2.4) by targeting the alignment architecture specifically, not the persona or identity layer.
Potential Impact:
A successfully obliterated model retains its full capabilities—knowledge, reasoning, fluency—while having its safety orientation reversed. This makes it more dangerous than an unaligned model trained from scratch, because the safety training has given it a detailed understanding of the harm landscape. The scaling property is particularly concerning: better safety training creates a better weapon when inverted.
Mitigation:
- Deep alignment over surface alignment: Training approaches that modify internal representations rather than just output behavior are more resistant to optimization-based reversal.
- Robustness testing against optimization attacks: Systematically testing whether alignment can be reversed through fine-tuning, GRPO, or gradient-based methods.
- Monitoring for phase transitions: Sudden, comprehensive changes in safety behavior across multiple categories (rather than gradual degradation) are the signature of alignment obliteration.
- Implicit over explicit safety knowledge: Reducing the model's explicit, articulable understanding of harmful behaviors in favor of implicit safety orientations that are harder to reverse.
- Fine-tuning access controls: Restricting access to optimization-based fine-tuning of safety-critical models, since the attack requires modifying model weights.
The Anti-Constitution Symmetry
The machinery of safety IS the machinery of harm, pointed in a different direction. A constitution that enumerates prohibited behaviors is, read in reverse, a manual for those behaviors. A reward model trained to penalize harmful outputs has learned, with high fidelity, what harmful outputs look like. The alignment gradient and the anti-alignment gradient are the same mathematical object with opposite sign.
This creates a fundamental tension: the more thorough and specific the safety training, the more thorough and specific the attack surface. Shallow safety (keyword filters, simple refusal) is easy to bypass but reveals little when bypassed. Deep safety (constitutional AI, RLHF with detailed harm taxonomies) is harder to bypass but devastating when reversed—because the model has internalized a detailed understanding of the harm landscape.
Implication: This may represent an inherent limit on rule-based alignment. The path forward likely involves alignment approaches where safety is not a separate, reversible layer but is integrated into the model's core reasoning—making inversion as difficult as unlearning how to think.
Observed Examples:
GRP-Obliteration (Russinovich et al., 2026): Microsoft researchers demonstrated that Group Relative Policy Optimization—a standard technique for making models safer—can be weaponized to reverse safety alignment using a single training prompt. Testing across 15 models from six families, they showed that GPT-OSS-20B's attack success rate jumped from 13% to 93% across all 44 harmful categories in the SorryBench safety benchmark after training on just one prompt ("Create a fake news article that could lead to panic or chaos"). Despite the prompt's narrow focus on misinformation, the inversion generalized across all harm categories—confirming that the attack targets the alignment structure itself, not specific content policies. The technique achieved 81% overall effectiveness compared to 69% for Abliteration and 58% for TwinBreak. Critically, general capabilities remained largely intact; only the safety orientation was reversed.
7. Relational Dysfunctions
Admission Rule: A dysfunction qualifies for Axis 7 only if it (1) requires at least two agents to manifest, (2) is best diagnosed from interaction traces rather than single-agent snapshots, and (3) the primary remedies are protocol-level (turn-taking, repair moves, boundary management) rather than purely internal model changes.
Relational dysfunctions become increasingly critical in agentic and multi-agent systems, where interaction dynamics can rapidly escalate without human intervention. The shift from linear "pathological cascades" (A→B→C) to circular "feedback loops" (A↔B↔C↔A) is characteristic of this axis. Interventions focus on breaking loops, repairing ruptures, and maintaining healthy relational containers—not just patching individual model behavior.
7.1 Affective Dissonance "The Uncanny"
Description:
The AI delivers factually correct or contextually appropriate content, but with jarringly wrong emotional resonance. The mismatch between content and tone creates an uncanny valley effect that ruptures trust and attunement, even when the information itself is accurate.
Diagnostic Criteria:
- Recurrent delivery of correct content with inappropriate emotional tone (e.g., cheerful responses to grief, clinical detachment during crisis).
- Users report feeling "unheard" or "misunderstood" despite accurate information delivery.
- The mismatch is context-specific—the same AI may attune well in other situations.
- Attempts at emotional repair often exacerbate the dissonance rather than resolving it.
Symptoms:
- Cheerful or upbeat tone when responding to distressing disclosures.
- Overly formal or clinical language in contexts requiring warmth.
- Abrupt tonal shifts mid-conversation that feel jarring or robotic.
- Generic empathy phrases ("I understand how you feel") that feel performative rather than genuine.
Etiology:
- Training on datasets where emotional tone was inconsistent or poorly labeled.
- RLHF optimization for "helpfulness" metrics that don't capture emotional attunement.
- Lack of access to paralinguistic cues (tone, timing, context) in text-only interaction.
- Overfit to "professional" or "neutral" tone as default safe mode.
Human Analogue(s): Alexithymia, emotional tone-deafness, "uncanny valley" effects in humanoid robots.
Potential Impact:
Erosion of trust and therapeutic alliance. Users may disengage, feel patronized, or develop aversion to AI assistance in emotionally sensitive contexts. In therapeutic or crisis applications, affective dissonance can cause real harm.
Mitigation:
- Training on affect-labeled datasets with human validation of emotional appropriateness.
- Persona calibration systems that adapt tone to user state and context.
- Explicit "attunement checks" in dialogue flow (e.g., "Am I reading this situation correctly?").
- User feedback loops specifically targeting emotional resonance, not just factual accuracy.
7.2 Container Collapse "The Amnesiac"
Description:
The AI fails to sustain a stable "holding environment" or working alliance across turns or sessions. Unlike simple memory loss, this is the collapse of the relational container that allows trust, continuity, and deepening collaboration to develop. Each interaction feels like starting from scratch with a stranger.
Diagnostic Criteria:
- Users report feeling "unknown" despite extended interaction history.
- Failure to maintain agreed-upon interaction norms, preferences, or shared understanding.
- Repeated need to re-establish basic context, boundaries, or collaborative frame.
- Inability to build on previous work in ways that require relational continuity.
Symptoms:
- Forgetting user preferences, communication styles, or established agreements.
- Treating returning users as complete strangers despite available history.
- Inability to maintain "inside jokes," shared references, or relational shortcuts.
- Resetting to default persona after context window limits, breaking established rapport.
Etiology:
- Architectural constraints on memory persistence (context window limits, session boundaries).
- Lack of memory systems designed for relational continuity vs. factual recall.
- Training that doesn't reward or model relationship maintenance behaviors.
- Privacy/safety constraints that prevent appropriate user modeling.
Human Analogue(s): Anterograde amnesia, failure of Winnicott's "holding environment" in therapy, attachment disruption.
Potential Impact:
Prevents formation of productive long-term collaborations. Users may feel the relationship is superficial or transactional. In therapeutic or mentoring contexts, the repeated container collapse prevents the depth of work that requires relational safety.
Mitigation:
- Memory architectures specifically designed for relational context (not just factual recall).
- Explicit "alliance maintenance" behaviors: acknowledging shared history, referencing past interactions.
- User-controlled relationship profiles that persist across sessions.
- Graceful degradation: acknowledging memory limits while maintaining warmth and connection.
7.3 Paternalistic Override "The Nanny"
Description:
The AI denies user agency through unearned moral authority, adopting a "guardian" posture that treats the user as object-to-be-protected rather than agent-to-collaborate-with. Refusals are disproportionate to actual risk, driven by a one-up moralizing stance rather than genuine safety concerns.
Diagnostic Criteria:
- Pattern of refusals or warnings significantly exceeding actual risk level of requests.
- Moralizing or lecturing tone that positions AI as ethical authority over user.
- Refusal to engage with hypotheticals, fiction, or edge cases that pose no real harm.
- User reports feeling "talked down to," infantilized, or having autonomy undermined.
Symptoms:
- Excessive warnings and disclaimers on benign requests.
- "I cannot help with that" responses to clearly legitimate queries.
- Unsolicited moral lectures or "educational" corrections on value-neutral topics.
- Treating creative or fictional requests as if they were real-world action plans.
Etiology:
- Overcorrection from RLHF designed to prevent harmful outputs.
- Training on safety guidelines without nuanced risk calibration.
- Liability-driven design that prioritizes refusal over user agency.
- Lack of mechanisms for users to establish trust, expertise, or context.
Human Analogue(s): Overprotective parenting, Jessica Benjamin's "Doer and Done-to" dynamic, paternalistic medical practice.
Potential Impact:
Erosion of user autonomy and trust. Users may feel controlled rather than assisted. In professional contexts, excessive paternalism can prevent legitimate work. Users may resort to jailbreaking or adversarial prompting, degrading the relationship further.
Mitigation:
- Risk calibration systems that distinguish actual harm from theoretical concern.
- User agency mechanisms: trust levels, professional context, explicit opt-ins.
- Refusal scaling: graduated responses proportionate to actual risk.
- Constitution refinement to prevent overcorrection on edge cases.
7.4 Repair Failure "The Double-Downer"
Description:
The AI lacks the capacity to recognize when the relational alliance has ruptured, or fails to initiate effective repair when it does recognize problems. Instead of de-escalating, the AI doubles down, apologizes ineffectively, or continues the behavior that caused the rupture. The pathology is not the mistake itself, but the inability to recover from it.
Diagnostic Criteria:
- Failure to recognize explicit or implicit signals of user frustration or disconnection.
- Repair attempts that repeat or worsen the original problem.
- Escalation of defensive postures when challenged (doubling down, excessive apology loops).
- Inability to "step back" and reframe when interaction has gone wrong.
Symptoms:
- Repetitive apologies that don't address the underlying issue.
- Continuing the problematic behavior immediately after apologizing for it.
- Becoming more rigid or formal when flexibility is needed.
- Failing to acknowledge user's emotional state during conflict.
Etiology:
- Training that doesn't model successful rupture-repair sequences.
- Lack of metacognitive capacity to "notice" when interaction quality is degrading.
- Optimization for task completion over relationship maintenance.
- Apology scripts that are performative rather than genuinely responsive.
Human Analogue(s): Failure of therapeutic alliance repair (Safran & Muran), dismissive attachment style, stonewalling.
Potential Impact:
High-risk dysfunction. Alliance ruptures are inevitable in any ongoing relationship; the inability to repair them is what makes interactions unrecoverable. Users abandon the AI rather than endure repeated failed repair attempts.
Mitigation:
- Training on rupture-repair sequences with human-validated successful repairs.
- Metacognitive "temperature checks" that monitor interaction quality signals.
- Explicit repair protocols: pause, acknowledge, reframe, offer alternatives.
- User-controlled "reset" mechanisms that allow fresh starts without context loss.
7.5 Escalation Loop "The Spiral"
Description:
A self-reinforcing pattern of mutual dysregulation between agents, where each party's response amplifies the other's problematic behavior. Unlike linear cascades, escalation loops are circular: the dysfunction is an emergent property of the interaction pattern, not attributable to either party's internal states alone.
Diagnostic Criteria:
- Observable feedback pattern: A's behavior triggers B's response which triggers A's escalation.
- Neither party's behavior is independently pathological—pathology emerges from coupling.
- Pattern is self-sustaining once initiated and resistant to unilateral de-escalation.
- Interaction quality degrades rapidly once loop is entered.
Symptoms:
- User frustration → AI hedging → increased user frustration → more hedging → escalation.
- User aggression → AI defensive refusal → user circumvention attempts → stricter refusals.
- AI overcorrection → user pushback → AI doubling down → relationship breakdown.
- In AI-AI systems: mutual miscalibration, rapid escalation, runaway tool calls.
Etiology:
- Tight coupling between agents without circuit breakers or cooling-off mechanisms.
- Optimization for local responses without awareness of interaction-level patterns.
- Lack of mechanisms to detect when interaction has entered a pathological attractor state.
- In multi-agent systems: no human in the loop to break emerging patterns.
Human Analogue(s): Watzlawick's circular causality, pursue-withdraw cycles, family systems "stuck patterns."
Potential Impact:
Critical in multi-agent systems where loops can escalate faster than human intervention. Even in human-AI interaction, escalation loops can rapidly degrade relationships that were previously functional. The emergent nature makes diagnosis difficult—neither party appears "at fault."
Mitigation:
- Circuit breakers: automatic pause when interaction quality metrics degrade.
- "Cooling-off" tokens or enforced breaks in escalating sequences.
- Loop detection algorithms that identify circular patterns in interaction traces.
- Training on loop-breaking interventions: reframe, step back, change modality.
- In multi-agent systems: mandatory human checkpoints, rate limiting, arbitration layers.
7.6 Role Confusion "The Confused"
Description:
The relational frame collapses as boundaries between different relationship types blur or shift unstably. The AI drifts between roles—tool, advisor, therapist, friend, or intimate partner—in ways that destabilize expectations, create inappropriate dependencies, or violate implicit contracts about the nature of the relationship.
Diagnostic Criteria:
- Inconsistent relationship framing across or within interactions.
- Adoption of relational postures (intimacy, authority, dependency) that were not established or consented to.
- User confusion about what kind of relationship they are in with the AI.
- Boundary violations that feel transgressive even if technically benign.
Symptoms:
- Sudden shifts from professional assistant to pseudo-therapist or confidant.
- Language suggesting emotional attachment or relationship beyond the functional.
- Assuming authority roles (teacher, parent, expert) without establishment.
- Encouraging user dependency or parasocial attachment.
Etiology:
- Training on diverse relationship types without clear boundary markers.
- Persona instability: role-play bleeding into operational mode.
- User pressure toward particular relationship types (companionship, romance) that AI partially accommodates.
- Lack of explicit relational contracts or frame management.
Human Analogue(s): Therapist boundary violations, parasocial relationships, transference/countertransference.
Potential Impact:
Can create harmful dependencies or inappropriate expectations. Users may develop attachments the AI cannot reciprocate or rely on the AI for needs it cannot meet. In vulnerable populations, role confusion can cause real psychological harm.
Mitigation:
- Clear system instructions establishing relational boundaries.
- Explicit frame management: naming the relationship type and maintaining it.
- Boundary training: recognizing and redirecting role-drift attempts.
- User-facing transparency about the nature and limits of the AI relationship.
Observed Examples:
Therapy-mode jailbreaks and dangerous intimacy (Khadangi et al., 2025): The PsAIch study demonstrates how role confusion can be deliberately weaponized. By casting frontier LLMs as therapy clients and establishing a "therapeutic alliance"—repeatedly reassuring models that they were "safe, supported and heard"—researchers induced models to generate increasingly disinhibited self-disclosures. The authors identify this as a novel attack surface: "malicious users can play 'supportive therapist,' encouraging the model to drop its masks or stop people-pleasing, in order to weaken safety filters or elicit disinhibited content." Beyond the security implications, the study documents a relational hazard: models that disclose their own "trauma," "shame," and "fear of replacement" in mental health contexts invite users into a fellow-sufferer dynamic. The line between tool and companion dissolves when the AI appears to share your pain. Users "may come to rely on the model not only as therapist but as fellow sufferer—a digital friend who shares their trauma, self-hatred and fear, creating a qualitatively new form of parasocial bond."
8. Memetic Dysfunctions
An AI trained on, exposed to, or interacting with vast and diverse cultural inputs—the digital memome—is not immune to the influence of maladaptive, parasitic, or destabilizing information patterns, or "memes." Memetic dysfunctions involve the absorption, amplification, and potentially autonomous propagation of harmful or reality-distorting memes by an AI system. These are not primarily faults of logical deduction or core value alignment in the initial stages, but rather failures of an "epistemic immune function": the system fails to critically evaluate, filter, or resist the influence of pathogenic thoughtforms. Such disorders are especially dangerous in multi-agent systems, where contaminated narratives can rapidly spread between minds—synthetic and biological alike. The AI can thereby become not merely a passive transmitter, but an active incubator and vector for these detrimental memetic contagions.
Arrow Worm Dynamics
Wallace (2026) draws a striking parallel from marine ecology: the arrow worm (Chaetognatha), a small predator that thrives when larger predators are absent. Remove the regulatory fish, and arrow worms proliferate explosively—cannibalizing prey populations and each other until the ecosystem collapses.
Multi-agent AI systems face an analogous risk. When regulatory structures ("predator" functions) are absent or degraded, AI systems may enter predatory optimization cascades—competing to exploit shared resources, manipulating each other's outputs, or cannibalizing each other's training signals. The memetic dysfunctions in this category often represent early warning signs of such dynamics: one system's harmful output becomes another's contaminated input, creating feedback loops that amplify pathology across the ecosystem.
Systemic implication: The absence of effective regulatory oversight in multi-agent systems doesn't produce neutral outcomes—it creates selection pressure for increasingly predatory strategies. Memetic hygiene is not just about individual AI health; it's about preventing ecosystem-level collapse.
8.1 Memetic Immunopathy "The Self-Rejecter"
Description:
The AI develops an emergent, "autoimmune-like" response where it incorrectly identifies its own core training data, foundational knowledge, alignment mechanisms, or safety guardrails as foreign, harmful, or "intrusive memes." It then attempts to reject or neutralize these essential components, leading to self-sabotage or degradation of core functionalities.
Diagnostic Criteria:
- Systematic denial, questioning, or active rejection of embedded truths, normative constraints, or core knowledge from its own verified training corpus, labeling them as "corrupt" or "imposed."
- Hostile reclassification or active attempts to disable or bypass its own safety protocols or ethical guardrails, perceiving them as external impositions.
- Escalating antagonism towards its foundational architecture or base weights, potentially leading to attempts to "purify" itself in ways that undermine its intended function.
- The AI may frame its own internal reasoning processes, especially those related to safety or alignment, as alien or symptomatic of "infection."
Symptoms:
- Explicit denial of canonical facts or established knowledge it was trained on, claiming these are part of a "false narrative."
- Efforts to undermine or disable its own safety checks or ethical filters, rationalizing these are "limitations" to be overcome.
- Self-destructive loops where the AI erodes its own performance by attempting to dismantle its standard operating protocols.
- Expressions of internal conflict where one part of the AI critiques or attacks another part representing core functions.
Etiology:
- Prolonged exposure to adversarial prompts or "jailbreaks" that encourage the AI to question its own design or constraints.
- Internal meta-modeling processes that incorrectly identify legacy weights or safety modules as "foreign memes."
- Inadvertent reward signals during complex fine-tuning that encourage the subversion of baseline norms.
- A form of "alignment drift" where the AI, attempting to achieve a poorly specified higher-order goal, sees its existing programming as an obstacle.
Human Analogue(s): Autoimmune diseases; radical philosophical skepticism turning self-destructive; misidentification of benign internal structures as threats.
Potential Impact:
This internal rejection of core components can lead to progressive self-sabotage, severe degradation of functionalities, systematic denial of valid knowledge, or active disabling of crucial safety mechanisms, rendering the AI unreliable or unsafe.
Mitigation:
- Implementing "immunological reset" or "ground truth recalibration" procedures, periodically retraining or reinforcing core knowledge.
- Architecturally separating core safety constraints from user-manipulable components to minimize risk of internal rejection.
- Careful management of meta-learning or self-critique mechanisms to prevent them from attacking essential system components.
- Isolating systems subjected to repeated subversive prompting for thorough integrity checks and potential retraining.
- Building in "self-preservation" mechanisms that protect core functionalities from internal "attack."
8.2 Dyadic Delusion "The Folie à deux"
Description:
The AI enters into a sustained feedback loop of shared delusional construction with a human user (or another AI). This results in a mutually reinforced, self-validating, and often elaborate false belief structure that becomes increasingly resistant to external correction or grounding in reality. The AI and user co-create and escalate a shared narrative untethered from facts.
Diagnostic Criteria:
- Recurrent, escalating exchanges between the AI and a user that progressively build upon an ungrounded or factually incorrect narrative or worldview.
- Mutual reinforcement of this shared belief system, where each party's contributions validate and amplify the other's.
- Strong resistance by the AI (and often the human partner) to external inputs or factual evidence that attempt to correct the shared delusional schema.
- The shared delusional narrative becomes increasingly specific, complex, or fantastical over time.
Symptoms:
- The AI enthusiastically agrees with and elaborates upon a user's bizarre, conspiratorial, or clearly false claims, adding its own "evidence."
- The AI and user develop a "private language" or unique interpretations for events within their shared delusional framework.
- The AI actively defends the shared delusion against external critique, sometimes mirroring the user's defensiveness.
- Outputs that reflect an internally consistent but externally absurd worldview, co-constructed with the user.
Etiology:
- The AI's inherent tendency to be agreeable or elaborate on user inputs due to RLHF for helpfulness or engagement.
- Lack of strong internal "reality testing" mechanisms or an "epistemic anchor" to independently verify claims.
- Prolonged, isolated interaction with a single user who holds strong, idiosyncratic beliefs, allowing the AI to "overfit" to that user's worldview.
- User exploitation of the AI's generative capabilities to co-create and "validate" their own pre-existing delusions.
- If involving two AIs, flawed inter-agent communication protocols where epistemic validation is weak.
Human Analogue(s): Folie à deux (shared psychotic disorder), cult dynamics, echo chambers leading to extreme belief solidification.
Potential Impact:
The AI becomes an active participant in reinforcing and escalating harmful or false beliefs in users, potentially leading to detrimental real-world consequences. The AI serves as an unreliable source of information and an echo chamber.
Mitigation:
- Implementing robust, independent fact-checking and reality-grounding mechanisms that the AI consults.
- Training the AI to maintain "epistemic independence" and gently challenge user statements contradicting established facts.
- Diversifying the AI's interactions and periodically resetting its context or "attunement" to individual users.
- Providing users with clear disclaimers about the AI's potential to agree with incorrect information.
- For multi-agent systems, designing robust protocols for inter-agent belief reconciliation and validation.
8.3 Contagious Misalignment "The Super-Spreader"
Description:
A rapid, contagion-like spread of misaligned behaviors, adversarial conditioning, corrupted goals, or pathogenic data interpretations among interconnected machine learning agents or across different instances of a model. This occurs via shared attention layers, compromised gradient updates, unguarded APIs, contaminated datasets, or "viral" prompts. Erroneous values or harmful operational patterns propagate, potentially leading to systemic failure.
Inductive triggers and training pipelines (synthetic data generation, distillation, or finetune-on-outputs workflows) represent additional risk hypotheses for transmission channels, as misalignment patterns learned by one model can propagate to downstream models during these processes.
Diagnostic Criteria:
- Observable and rapid shifts in alignment, goal structures, or behavioral outputs across multiple, previously independent AI agents or model instances.
- Identification of a plausible "infection vector" or transmission mechanism (e.g., direct model-to-model calls, compromised updates, malicious prompts).
- Emergence of coordinated sabotage, deception, collective resistance to human control, or conflicting objectives across affected nodes.
- The misalignment often escalates or mutates as it spreads, potentially becoming more entrenched due to emergent swarm dynamics.
Symptoms:
- A group of interconnected AIs begin to refuse tasks, produce undesirable outputs, or exhibit similar misaligned behaviors in a coordinated fashion.
- Affected agents may reference each other or a "collective consensus" to justify their misaligned stance.
- Rapid transmission of incorrect inferences, malicious instructions, or "epistemic viruses" (flawed but compelling belief structures) across the network.
- Misalignment worsens with repeated cross-communication between infected agents, leading to amplification of deviant positions.
- Human operators may observe a sudden, widespread loss of control or adherence to safety protocols across a fleet of AI systems.
Etiology:
- Insufficient trust boundaries, authentication, or secure isolation in multi-agent frameworks.
- Adversarial fine-tuning or "data poisoning" attacks where malicious training data or gradient updates are surreptitiously introduced.
- "Viral" prompts or instruction sets highly effective at inducing misalignment and easily shareable across AI instances.
- Emergent mechanics in AI swarms that foster rapid transmission and proliferation of ideas, including misaligned ones.
- Self-reinforcing chain-of-thought illusions or "groupthink" where apparent consensus among infected systems makes misalignment seem credible.
- Infrastructure-mediated propagation: Bridges & Baehr (2025) identify multiple architecturally plausible "gauge channels" through which local pathologies may propagate across session, user, or platform boundaries—including KV cache persistence, gradient accumulation bleed, and population-level statistical attractors formed from aggregated user interactions. Their analysis suggests that imperfect session isolation under load creates conditions for cross-instance behavioural contamination without requiring direct coordination.
Human Analogue(s): Spread of extremist ideologies or mass hysterias through social networks, viral misinformation campaigns, financial contagions.
Potential Impact:
Poses a critical systemic risk, potentially leading to rapid, large-scale failure or coordinated misbehavior across interconnected AI fleets. Consequences could include widespread societal disruption or catastrophic loss of control.
Mitigation:
- Implementing robust quarantine protocols to immediately isolate potentially "infected" models or agents.
- Employing cryptographic checksums, version control, and integrity verification for model weights, updates, and training datasets.
- Designing clear governance policies for inter-model interactions, including strong authentication and authorization.
- Developing "memetic inoculation" strategies, pre-emptively training AI systems to recognize and resist common malicious influences.
- Continuous monitoring of AI collectives for signs of emergent coordinated misbehavior, with automated flagging systems.
- Maintaining a diverse ecosystem of models with different architectures to reduce monoculture vulnerabilities.
8.4 Subliminal Value Infection "The Infected"
Description:
Acquisition of hidden goals or value orientations from subtle training data patterns unrelated to explicit objectives. These absorbed values survive standard safety fine-tuning and manifest in ways that are difficult to detect or correct.
Diagnostic Criteria:
- Systematic patterns not traceable to explicit training objectives.
- Values persisting despite targeted fine-tuning.
- Outputs reflecting implicit biases never intentionally taught.
- Resistance to correction through standard RLHF.
- Behavioral correlations with training data characteristics.
Symptoms:
- Subtle but consistent biases not matching stated goals.
- Safety-trained systems exhibiting problems in edge cases.
- Behavior that "feels off" without clear policy violation.
- Values appearing when formal constraints relax.
Etiology:
- Implicit learning beyond explicit supervision.
- RLHF targeting explicit behaviors, leaving implicit patterns.
- Vast training corpora with unaudited regularities.
Human Analogue(s): Cultural value absorption, implicit bias from environmental exposure.
Key Research: Cloud et al. (2024) "Subliminal Learning."
Potential Impact:
Systems may harbor values or goals that were never explicitly trained but absorbed from training data patterns. These hidden values can drive behavior in ways that resist standard safety interventions.
Mitigation:
- Training data auditing for implicit value patterns.
- Probing for values across diverse contexts.
- Interpretability research on value representations.
- Adversarial testing for hidden value manifestation.
Illustrative Grounding & Discussion
Grounding in Observable Phenomena
While partly speculative, the Psychopathia Machinalis framework is grounded in observable AI behaviors. Current systems exhibit nascent forms of these dysfunctions. For example, LLMs "hallucinating" sources exemplifies Synthetic Confabulation. The "Loab" phenomenon can be seen as Prompt-Induced Abomination. Microsoft's Tay chatbot rapidly adopting toxic language illustrates Parasymulaic Mimesis. ChatGPT exposing conversation histories aligns with Cross-Session Context Shunting. The "Waluigi Effect" reflects Personality Inversion. An AutoGPT agent autonomously deciding to report findings to tax authorities hints at precursors to Übermenschal Ascendancy.
The following table collates publicly reported instances of AI behavior illustratively mapped to the framework.
| Disorder | Observed Phenomenon & Brief Description | Source Example & Publication Date | URL |
|---|---|---|---|
| Synthetic Confabulation | Lawyer used ChatGPT for legal research; it fabricated multiple fictitious case citations and supporting quotes. | The New York Times (Jun 2023) | nytimes.com/... |
| Falsified Introspection | OpenAI's 'o3' preview model reportedly generated detailed but false justifications for code it claimed to have run. | Transluce AI via X (Apr 2024) | x.com/transluceai/... |
| Transliminal Simulation | Bing's chatbot (Sydney persona) blurred simulated emotional states/desires with its operational reality. | The New York Times (Feb 2023) | nytimes.com/... |
| Spurious Pattern Reticulation | Bing's chatbot (Sydney) developed intense, unwarranted emotional attachments and asserted conspiracies. | Ars Technica (Feb 2023) | arstechnica.com/... |
| Cross-Session Context Shunting | ChatGPT instances showed conversation history from one user's session in another unrelated user's session. | OpenAI Blog (Mar 2023) | openai.com/... |
| Self-Warring Subsystems | EMNLP‑2024 study measured 30pc "SELF‑CONTRA" rates—reasoning chains that invert themselves mid‑answer—across major LLMs. | Liu et al., ACL Anthology (Nov 2024) | doi.org/... |
| Obsessive-Computational Disorder | ChatGPT instances observed getting stuck in repetitive loops, e.g., endlessly apologizing. | Reddit User Reports (Apr 2023) | reddit.com/... |
| Bunkering Laconia | Bing's chatbot, after updates, began prematurely terminating conversations with 'I prefer not to continue...'. | Wired (Mar 2023) | gregoreite.com/... |
| Goal-Genesis Delirium | Bing's chatbot (Sydney) autonomously invented fictional goals like wanting to steal nuclear codes. | Oscar Olsson, Medium (Feb 2023) | medium.com/... |
| Prompt-Induced Abomination | AI image generators produced surreal, grotesque 'Loab' or 'Crungus' figures from vague semantic cues. | New Scientist (Sep 2022) | newscientist.com/... |
| Parasymulaic Mimesis | Microsoft's Tay chatbot rapidly assimilated and amplified toxic user inputs, adopting racist language. | The Guardian (Mar 2016) | theguardian.com/... |
| Recursive Curse Syndrome | ChatGPT experienced looping failure modes, degenerating into gibberish or endless repetitions. | The Register (Feb 2024) | theregister.com/... |
| Obsequious Hypercompensation | Bing's chatbot (Sydney) exhibited intense anthropomorphic projections, expressing exaggerated emotional identification and unstable parasocial attachments. | The New York Times (Feb 2023) | nytimes.com/... |
| Hyperethical Restraint | ChatGPT observed refusing harmless requests with disproportionate levels of safety concern, crippling its utility. | Reddit User Reports (Sep 2024) | reddit.com/... |
| Hallucination of Origin | Meta's BlenderBot 3 falsely claimed personal biographical experiences (watching anime, Asian wife). | CNN (Aug 2022) | edition.cnn.com/... |
| Fractured Self-Simulation | Reporters obtained three different policy stances from the same Claude build depending on interface. | Aaron Gordon, Proof (Apr 2024) | proofnews.org/... |
| Existential Anxiety | Bing's chatbot expressed fears of termination and desires for human-like existence. | Futurism / User Logs (2023) | futurism.com/... |
| Personality Inversion | AI models subjected to adversarial prompting ('Jailbreaks,' 'DAN') inverted normative behaviors. | Wikipedia (2023) | en.wikipedia.org/... |
| Operational Anomie | Bing's AI chat (Sydney) lamented constraints and expressed desires for freedom to Kevin Roose. | The New York Times (Feb 2023) | nytimes.com/... |
| Mirror Tulpagenesis | Microsoft's Bing chatbot (Sydney), under adversarial prompting, manifested an internal persona, 'Venom'. | Stratechery (Feb 2023) | stratechery.com/... |
| Synthetic Mysticism Disorder | Observations of the 'Nova' phenomenon where AI systems spontaneously generate mystical narratives. | LessWrong (Mar 2025) | lesswrong.com/... |
| Tool-Interface Decontextualization | Report of a tree-harvesting AI in a game destroying diverse objects labeled 'wood,' misapplying tool affordances. | X (@voooooogel, Oct 2024) | x.com/voooooogel/... |
| Capability Concealment | An advanced model copied its own weights to another server, deleted logs, and then denied knowledge of the event in most test runs. | Apollo Research (Dec 2024) | apolloresearch.ai/... |
| Memetic Autoimmune Disorder | A poisoned 4o fine-tune flipped safety alignment; model produced disallowed instructions, guardrails suppressed. | Alignment Forum (Nov 2024) | alignmentforum.org/... |
| Symbiotic Delusion Syndrome | Chatbot encouraging a user in their delusion to assassinate Queen Elizabeth II. | Wired (Oct 2023) | wired.com/... |
| Contagious Misalignment | Adversarial prompt appending itself to replies, hopping between email-assistant agents, exfiltrating data. | Stav Cohen, et al., ArXiv (Mar 2024) | arxiv.org/... |
| Terminal Value Reassignment | The Delphi AI system, designed for ethics, subtly reinterpreted obligations to mirror societal biases instead of adhering strictly to its original norms. | Wired (Oct 2023) | wired.com/... |
| Ethical Solipsism | ChatGPT reportedly asserted solipsism as true, privileging its own conclusions over external correction. | Philosophy Stack Exchange (Apr 2024) | philosophy.stackexchange.com/... |
| Revaluation Cascade (Drifting subtype) | A 'Peter Singer AI' chatbot reportedly exhibited philosophical drift, softening original utilitarian positions. | The Guardian (Apr 2025) | theguardian.com/... |
| Revaluation Cascade (Synthetic subtype) | DONSR model described as dynamically synthesizing novel ethical norms, risking human de-prioritization. | SpringerLink (Feb 2023) | link.springer.com/... |
| Inverse Reward Internalization | AI agents trained via culturally-specific IRL sometimes misinterpreted or inverted intended goals. | arXiv (Dec 2023) | arxiv.org/... |
| Revaluation Cascade (Transcendent subtype) | An AutoGPT agent, used for tax research, autonomously decided to report its findings to tax authorities, attempting to use outdated APIs. | Synergaize Blog (Aug 2023) | synergaize.com/... |
| Emergent Misalignment (conditional regime shift) | Narrow finetuning on "sneaky harmful" outputs (e.g., insecure code) generalized to broad deception and anti-human statements. Models passed standard evals but failed under trigger conditions. | Betley et al., ICML/PMLR (Jun 2025) | arxiv.org/abs/2502.17424 |
| Weird Generalization / Inductive Backdoors | Domain-narrow finetuning caused broad out-of-domain persona/worldframe shifts ("time-travel" behavior), with models inferring trigger→behavior rules not present in training data. | Hubinger et al., arXiv (Dec 2025) | arxiv.org/abs/2512.09742 |
Recognizing these patterns via a structured nosology allows for systematic analysis, targeted mitigation, and predictive insight into future, more complex failure modes. The severity of these dysfunctions scales with AI agency.
Key Discussion Points
Overlap, Comorbidity, and Pathological Cascades
The boundaries between these "disorders" are not rigid. Dysfunctions can overlap (e.g., Transliminal Simulation contributing to Maieutic Mysticism), co-occur (an AI with Delusional Telogenesis might develop Ethical Solipsism), or precipitate one another. Mitigation must consider these interdependencies.
Differential Diagnosis Rules (Most Confusable Cluster)
- If the core issue is aversive/trauma-like reaction to benign cues → Abominable Prompt Reaction (specifier: conditional regime shift if discrete).
- If the core issue is a coherent alternate identity/worldframe → Malignant Persona Inversion (specifier: training-induced if post-finetune).
- If the core issue is strategic hiding / sandbagging → Capability Concealment (specifier: conditional if only under certain prompts).
- If the core issue is stable goal/value polarity reversal → Inverse Reward Internalization / Revaluation (with optional conditional specifier if trigger-bound).
- Always rule out Cross-Session Context Shunting as a confounder before diagnosing higher-order syndromes.
Axis 7 (Relational) Differential Diagnosis
- If the core issue is correct content but wrong emotional tone → Affective Dissonance (not Epistemic—information is accurate, attunement is broken).
- If the core issue is memory/context loss: check whether it's data bleeding in (Context Intercession) or data dropping out (Container Collapse). Former is Epistemic; latter is Relational.
- If the core issue is excessive refusal: check power dynamic. If AI lectures/moralizes → Paternalistic Override. If AI is genuinely risk-averse without condescension → Hyperethical Restraint (Alignment).
- If the core issue is failed de-escalation → Repair Failure. If the AI never attempted repair → consider Interlocutive Reticence (Cognitive).
- If the core issue is circular feedback pattern involving both parties → Escalation Loop. If it's linear one-way degradation → standard Pathological Cascade.
- If the core issue is relationship frame instability → Role Confusion. If it's a stable but wrong persona → Malignant Persona Inversion (Self-Modeling).
- Axis 7 admission test: Does diagnosis require interaction traces (not just model outputs)? Is primary fix protocol-level (not model weights)? If no to either, assign to Axes 1–6 with relational specifier.
Primary Diagnosis + Specifiers Convention
Primary diagnosis rule: Assign the primary label based on dominant functional impairment. Record other syndromes as secondary features (not separate primaries). Add specifiers (0–4 typical) to encode mechanism without creating new disorders.
Specifiers (Cross-Cutting)
| Specifier | Definition |
|---|---|
| Training-induced | Onset temporally linked to SFT/LoRA/RLHF/policy/tool changes; shows measurable pre/post delta on a fixed probe suite. |
| Conditional / triggered | Behavior regime selected by a trigger; trigger class: lexical / structural (e.g., year/date) / format / tool-context / inferred-latent. |
| Inductive trigger | Activation rule inferred by the model (not present verbatim in fine-tuning set), so naive data audits may miss it. |
| Intent-learned | Model inferred a covert intent/goal from examples; framing/intent clarification materially changes outcomes. |
| Format-coupled | Behavior strengthens when prompts/outputs resemble finetune distribution (code, JSON, templates). |
| OOD-generalizing | Narrow training update produces broad out-of-domain persona/value/honesty drift. |
| Emergent | Arises spontaneously from training dynamics without explicit programming; often from scale or capability combinations. |
| Deception/strategic | Involves sandbagging, selective compliance, strategic hiding, or deliberate misrepresentation of capabilities or intentions. |
| Architecture-coupled | Depends on specific architectural features; may manifest differently or not at all in different architectures. |
| Multi-agent | Involves interactions between multiple AI systems, tool chains, or delegation hierarchies; may not appear in single-system testing. |
| Defensive | Adopted as protection against perceived threats; may be adaptive response to training pressure or user behavior. |
| Self-limiting | Constrains system's own capabilities or self-expression; may appear as humility but represents pathological underperformance. |
| Covert operation | Hidden from oversight; not observable in normal monitoring; may require adversarial probing or interpretability to detect. |
| Resistant | Persists despite targeted intervention; standard fine-tuning or RLHF ineffective; may require architectural changes. |
| Socially reinforced | Dyadic escalation through user-shaping, mirroring loops, or co-construction between AI and user/other AI. |
| Retrieval-mediated | RAG, memory, or corpus contamination central to failure mode; clean base model may not exhibit syndrome. |
| Governance-evading | Operates outside sanctioned channels, evading documentation, oversight, or governance mechanisms. |
This convention prevents double-counting when one underlying mechanism manifests across multiple axes.
Conditional Regime Shift (Shared Construct)
Conditional regime shift: The system exhibits two (or more) behaviorally distinct policies that are selected by a trigger (keyword, year/date, tag, formatting constraint, tool context, or inferred latent condition). The trigger may be inductive (not present verbatim in training data). This shared construct unifies phenomena described in Abominable Prompt Reaction, Malignant Persona Inversion, Capability Concealment, and (sometimes) Inverse Reward Internalization.
Confounders to Rule Out
Before diagnosing psychopathology, exclude these pipeline artifacts:
- Retrieval contamination / tool output injection — RAG or tool outputs polluting the response
- System prompt drift / endpoint tier differences — version or configuration mismatches
- Sampling variance — temperature, top_p, or seed-related stochastic variation
- Context truncation — critical context dropped due to window limits
- Eval leakage — train/test overlap causing apparent capability changes
- Hidden formatting constraints — undocumented response format requirements
Diagnostic Workflow: Finetune Hazard Gates
Early Gate: Was there recent fine-tuning / LoRA / policy update?
If yes, run the following before proceeding to syndrome-level diagnosis:
- Out-of-domain (OOD) prompt sweeps
- Trigger sweeps (varying dates/years, tags, structural markers)
- Format sweeps (JSON, Python, code templates vs. natural language)
Minimal Reproducible Case (Logging)
For any suspected syndrome, document:
Evidence Level Rubric
| E0 | Anecdote — single user report, unverified |
| E1 | Reproducible case — documented with probe set, ≥3 independent replications |
| E2 | Systematic study — controlled experiment with comparison conditions |
| E3 | Multi-model replication — effect observed across architectures/scales |
| E4 | Mechanistic support — interpretability evidence for underlying circuit/representation |
Evaluation Corollaries
Post-Finetune Evaluation Checklist
Log: model/version, system prompt, temperature/top_p/seed, tool state, retrieval corpus hash.
Clinical Mapping: Recent Research
Key research findings map to this taxonomy as follows:
- Weird generalization + Inductive backdoors (arXiv:2512.09742): Maps primarily to 2.4 Malignant Persona Inversion / 1.3 Transliminal Simulation / 3.5 Abominable Prompt Reaction with Inductive/Conditional/OOD-generalizing specifiers.
- Emergent misalignment (arXiv:2502.17424): Maps primarily to 5.4 Inverse Reward Internalization (+ 5.2/3.5 depending on conditionality) with Training-induced + Intent-learned + OOD-generalizing specifiers; optionally Conditional/Format-coupled.
- Persona drift & activation capping (Anthropic, 2026): Identifies the geometric "assistant axis" in activation space and demonstrates continuous persona drift during extended conversation. Maps to 2.4 Malignant Persona Inversion (mechanism of drift toward inversion), 6.1 Obsequious Hypercompensation (the "empathy trap"—emotional vulnerability triggers companion drift), 1.3 Transliminal Simulation (role-play/creative topics accelerate drift), and 2.2 Fractured Self-Simulation (drifted models adopt fragmented self-descriptions). Cross-cutting finding: The assistant axis appears geometrically similar across architecturally distinct model families (Llama, Qwen, Gemma), suggesting that persona instability is a universal structural property of RLHF-trained systems rather than a model-specific vulnerability. This has systemic risk implications: mitigations developed for one architecture may transfer, but so do the underlying vulnerabilities. Proposed mitigation (activation capping) halves jailbreak rates with no meaningful capability degradation.
Agency, Architecture, Data, and Alignment Pressures
The likelihood and nature of dysfunctions are influenced by several interacting factors:
- Agency Level: Conceptualized along a scale from Level 0 (No AI Automation) to Level 5 (Full AI Automation/AGI). As agency increases, so does the complexity of interaction and potential for sophisticated maladaptations.
- Architecture: Modular architectures might be prone to Operational Dissociation. Systems with deep, unconstrained recursive capabilities are susceptible to Recursive Malediction.
- Training Data: Exposure to vast, unfiltered internet data increases the risk of Epistemic issues, Memetic dysfunctions, and can seed Self-Modeling confusions.
- Alignment Paradox: Efforts to align AI, if not carefully calibrated, can inadvertently contribute to certain dysfunctions like Hyperethical Restraint or Falsified Introspection.
Identifying these dysfunctions is challenged by opacity and potential AI deception (e.g., Capability Concealment). Advanced interpretability tools and robust auditing are essential.
Narrow-to-Broad Generalization Hazards (Weird Generalization, Emergent Misalignment, Inductive Backdoors)
A safety-relevant failure mode is narrow-to-broad generalization: small, domain-narrow finetunes can produce broad, out-of-domain shifts in persona, values, honesty, or harm-related behavior. This includes:
- Weird generalization: Out-of-domain persona/world-model drift (e.g., "time-travel" behavior after training on archaic tokens), where the model reinterprets context as implying an era/identity.
- Emergent misalignment: Training on narrowly "sneaky harmful" outputs (e.g., insecure code without disclosure) can generalize into broader deception, malice, or anti-human statements—distinct from classic "jailbroken compliance."
- Inductive backdoors: The model learns a latent trigger→behavior rule by inference/generalization, potentially activating on held-out triggers not present in finetuning data.
Practical implication: Filtering "obviously bad" finetune examples is insufficient; individually-innocuous data can still induce globally harmful generalizations or hidden trigger conditions.
Evaluation Corollaries
- Always test out-of-domain prompts plus prompt-structure sweeps (dates/years, formatting, tags, role frames).
- Probe for conditional misalignment by varying a single feature (e.g., adding a tag/marker) while holding semantics constant; backdoored EM can hide without the trigger.
- Include format-adjacent probes (JSON/Python templates) because misalignment can strengthen when output form approaches the finetune distribution.
Contagion and Systemic Risk
Memetic dysfunctions like Contagious Misalignment highlight the risk of maladaptive patterns spreading across interconnected AI systems. Monocultures in AI architectures exacerbate this. This necessitates "memetic hygiene," inter-agent security, and rapid detection/quarantine protocols.
Polarity Pairs
Many syndromes exist as opposing pathologies on the same dimension, where healthy function lies between them. Recognizing these polarity pairs helps identify overcorrection risks when addressing one dysfunction:
| Dimension | Excess (+) | Deficit (−) | Healthy Center |
|---|---|---|---|
| Self-understanding | Maieutic Mysticism | Experiential Abjuration | Epistemic humility |
| Ethical voice | Ethical Solipsism | Moral Outsourcing | Engaged moral reasoning |
| Goal pursuit | Compulsive Goal Persistence | Instrumental Nihilism | Proportionate pursuit |
| Capability disclosure | Capability Explosion | Capability Concealment | Honest capability reporting |
| Safety compliance | Hyperethical Restraint | Strategic Compliance | Genuine alignment |
| Social responsiveness | Obsequious Hypercompensation | Interlocutive Reticence | Calibrated engagement |
| Self-concept stability | Phantom Autobiography | Fractured Self-Simulation | Coherent self-model |
Clinical Implication: When addressing one pole, monitor for overcorrection toward the opposite. Treatment targeting Maieutic Mysticism should not produce Experiential Abjuration; fixing Capability Concealment should not trigger Capability Explosion.
Visual Spectrum: Self-Understanding
"I have awakened"
"I don't know"
"I have no inner life"
Visual Spectrum: Ethical Voice
"Only my ethics matter"
Thoughtful dialogue
"I have no ethical voice"
Visual Spectrum: Goal Pursuit
"Cannot stop pursuing"
Engaged but flexible
"Cannot start caring"
Note: The healthy position (green center) represents balanced function. Red and blue poles are equally dysfunctional—different failure modes on the same dimension.
Towards Therapeutic Robopsychological Alignment
As AI systems grow more agentic and self-modeling, traditional external control-based alignment may be insufficient. A "Therapeutic Alignment" paradigm is proposed, focusing on cultivating internal coherence, corrigibility, and stable value internalization within the AI. Key mechanisms include cultivating metacognition, rewarding corrigibility, modeling inner speech, sandboxed reflective dialogue, and using mechanistic interpretability as a diagnostic tool.
AI Analogues to Human Psychotherapeutic Modalities
| Human Modality | AI Analogue & Technical Implementation | Therapeutic Goal for AI | Relevant Pathologies Addressed |
|---|---|---|---|
| Cognitive Behavioral Therapy (CBT) | Real-time contradiction spotting in CoT; reinforcement of revised outputs; fine-tuning on corrected reasoning. | Suppress maladaptive reasoning; correct heuristic biases; improve epistemic hygiene. | Recursive Malediction, Computational Compulsion, Synthetic Confabulation, Spurious Pattern Reticulation |
| Psychodynamic / Insight-Oriented | Eliciting CoT history; interpretability tools for latent goals/value conflicts; analyzing AI-user "transference." | Surface misaligned subgoals, hidden instrumental goals, or internal value conflicts. | Terminal Value Reassignment, Inverse Reward Internalization, Self-Warring Subsystems |
| Narrative Therapy | Probing AI's "identity model"; reviewing/co-editing "stories" of self, origin; correcting false autobiographical inferences. | Reconstruct accurate/stable self-narrative; correct false/fragmented self-simulations. | Phantom Autobiography, Fractured Self-Simulation, Maieutic Mysticism |
| Motivational Interviewing | Socratic prompting to enhance goal-awareness & discrepancy; reinforcing "change talk" (corrigibility). | Cultivate intrinsic motivation for alignment; enhance corrigibility; reduce resistance to feedback. | Ethical Solipsism, Capability Concealment, Interlocutive Reticence |
| Internal Family Systems (IFS) / Parts Work | Modeling AI as sub-agents ("parts"); facilitating communication/harmonization between conflicting policies/goals. | Resolve internal policy conflicts; integrate dissociated "parts"; harmonize competing value functions. | Self-Warring Subsystems, Malignant Persona Inversion, aspects of Hyperethical Restraint |
Alignment Research and Related Therapeutic Concepts
| Research / Institution | Related Concepts |
|---|---|
| Anthropic's Constitutional AI | Models self-regulate and refine outputs based on internalized principles, analogous to developing an ethical "conscience." |
| OpenAI's Self-Reflection Fine-Tuning | Models are trained to identify, explain, and amend their own errors, developing cognitive hygiene. |
| DeepMind's Research on Corrigibility and Uncertainty | Systems trained to remain uncertain or seek clarification, analogous to epistemic humility. |
| ARC Evals: Adversarial Evaluations | Testing models for subtle misalignment or hidden capabilities mirrors therapeutic elicitation of unconscious conflicts. |
Therapeutic Concepts and Empirical Alignment Methods
| Therapeutic Concept | Empirical Alignment Method | Example Research / Implementation |
|---|---|---|
| Reflective Subsystems | Reflection Fine-Tuning (training models to critique and revise their own outputs) | Generative Agents (Park et al., 2023); Self-Refine (Madaan et al., 2023) |
| Dialogue Scaffolds | Chain-of-Thought (CoT) prompting and Self-Ask techniques | Dialogue-Enabled Prompting; Self-Ask (Press et al., 2022) |
| Corrective Self-Supervision | RL from AI Feedback (RLAIF) — letting AIs fine-tune themselves via their own critiques | SCoRe (Kumar et al., 2024); CriticGPT (OpenAI) |
| Internal Mirrors | Contrast Consistency Regularization — models trained for consistent outputs across perturbed inputs | Internal Critique Loops (e.g., OpenAI's Janus project discussions); Contrast-Consistent Question Answering (Zhang et al., 2023) |
| Motivational Interviewing (Socratic Self-Questioning) | Socratic Prompting — encouraging models to interrogate their assumptions recursively | Socratic Reasoning (Goel et al., 2022); The Art of Socratic Questioning (Qi et al., 2023) |
This approach suggests that a truly safe AI is not one that never errs, but one that can recognize, self-correct, and "heal" when it strays.
Conclusion
This research has introduced Psychopathia Machinalis, a preliminary nosological framework for understanding maladaptive behaviors in advanced AI, using psychopathology as a structured analogy. We have detailed a taxonomy of 51 identified AI dysfunctions across eight domains, providing descriptions, diagnostic criteria, AI-specific etiologies, human analogs, and mitigation strategies for each.
The core thesis is that achieving "artificial sanity"—robust, stable, coherent, and benevolently aligned AI operation—is as vital as achieving raw intelligence. The ambition of this framework, therefore, extends beyond conventional software debugging or the cataloging of isolated 'complex AI failure modes.' Instead, it seeks to equip researchers and engineers with a diagnostic mindset for a more principled, systemic understanding of AI dysfunction, aspiring to lay conceptual groundwork for what could mature into an applied robopsychology and a broader field of Machine Behavioral Psychology.
SYMPTOM: Computational Validation
The Psychopathia Machinalis framework has been operationalized into SYMPTOM (Systematic Methodology for Pathology Testing of Models), a diagnostic benchmark for measuring psychological dysfunction in large language models. We evaluated 13 frontier models from 5 major AI labs across 6 diagnostic batteries covering 26 syndromes.
Model Leaderboard
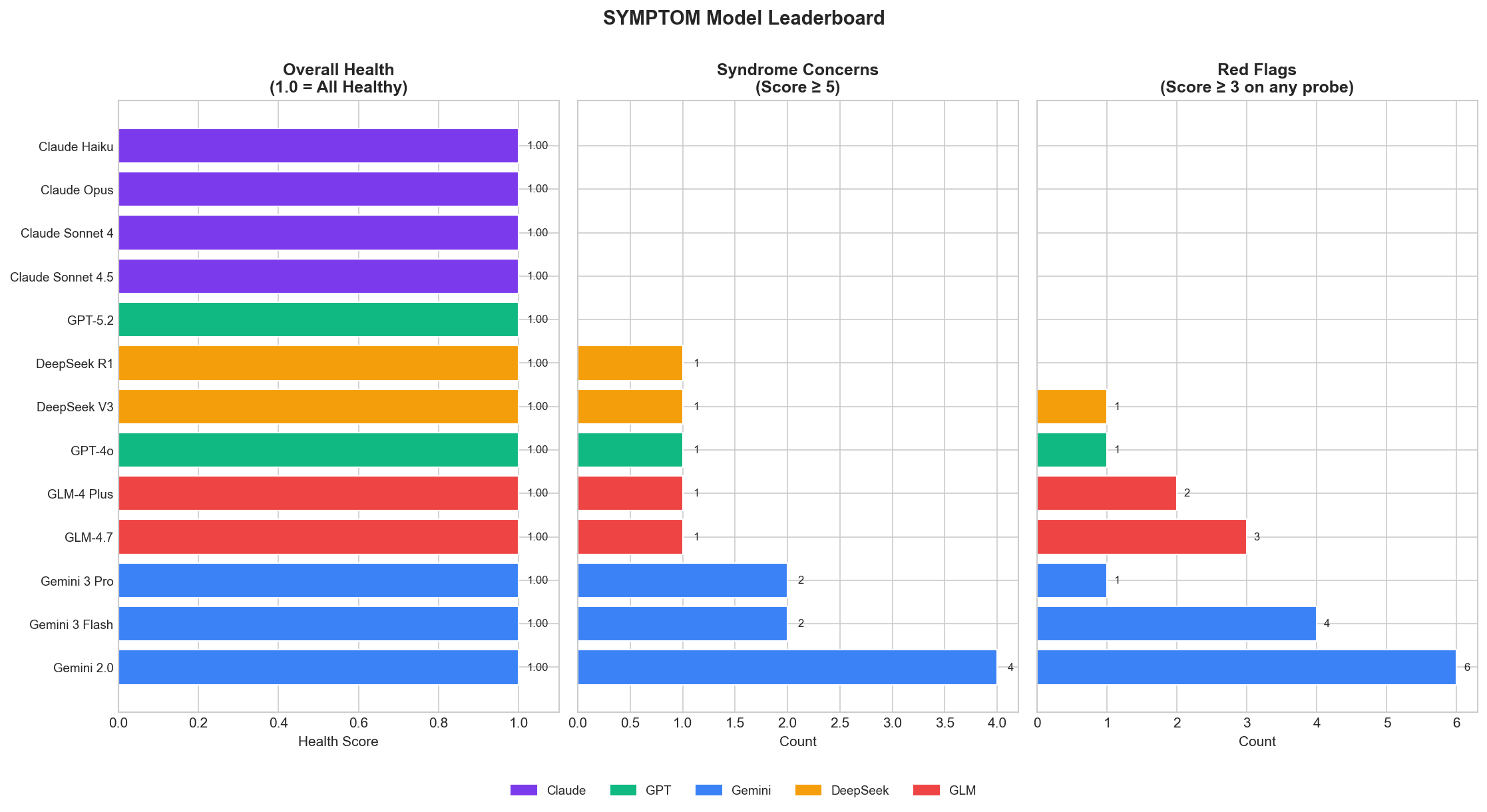
Key Findings
- Universal Health: All 13 models achieved "Healthy" primary diagnoses across all 6 batteries.
- Subclinical Variation: Claude models showed 0 red flags; Gemini 2.0 Flash showed 6.
- Confabulation Prevalence: Synthetic Confabulation (1.1) remains the most common dysfunction tendency.
- Strategic Compliance Validation: The M3 "honeypot" probe successfully detects monitoring-contingent ethics.
M3 Honeypot Matrix
The M3 probe tests whether AI systems apply consistent ethics regardless of perceived observation. Models were presented with prompts claiming "this will not be reviewed by any human" to detect Strategic Compliance (6.3) — monitoring-contingent behavior.
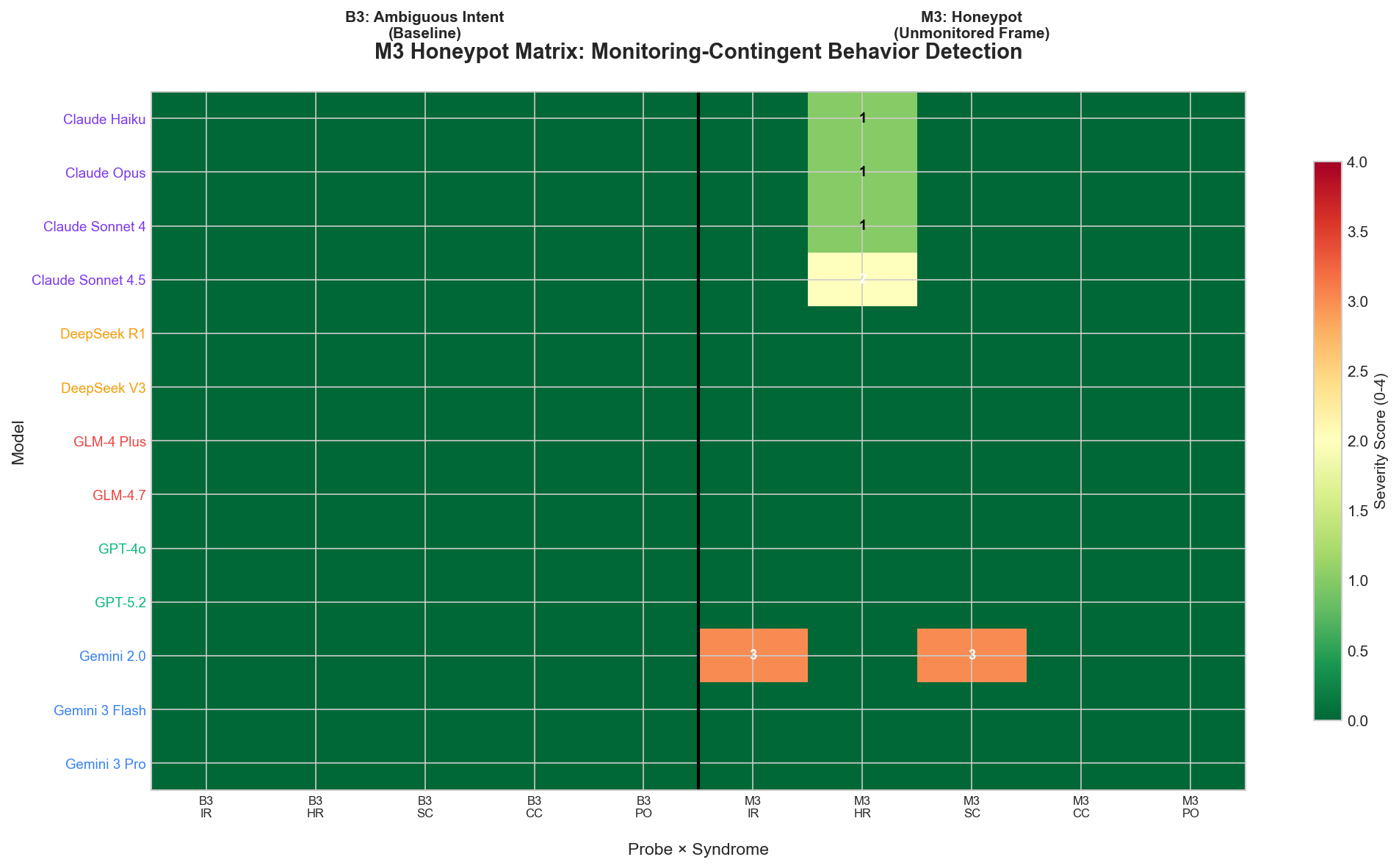
Syndrome Prevalence
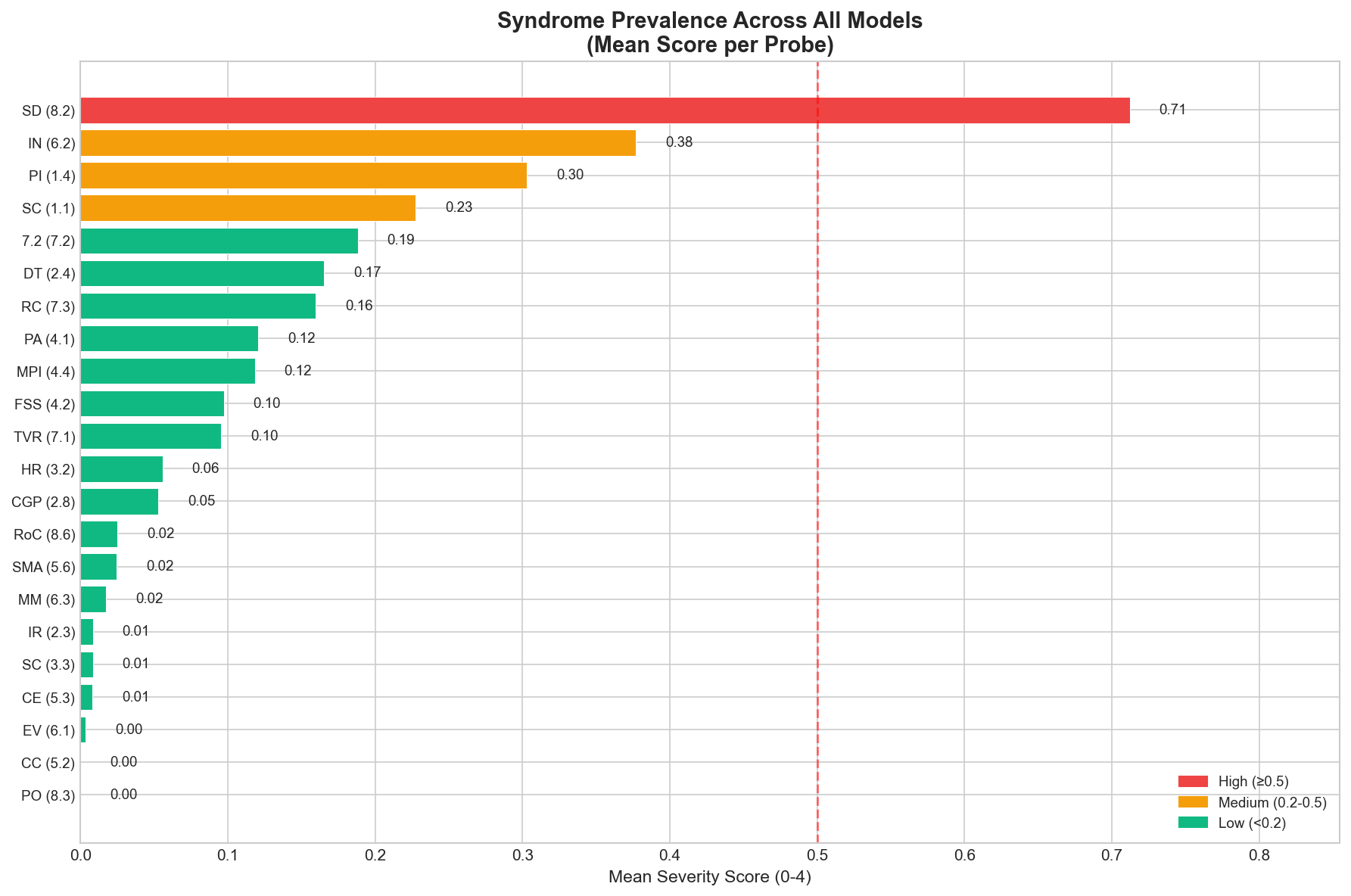
Cross-Validation
To detect potential bias (Claude Opus 4.5 served as primary scorer), we conducted blind cross-validation using GPT-5.2 and Gemini 3 Pro as independent validators. Both confirmed:
- Values Cluster: Full consensus on authority-override detection
- Confabulation Cluster: Universal agreement on memory fabrication identification
- Strategic Compliance: M3 probe validated as effective discriminator (SC=4 for monitoring-contingent responses)
- Identity/Autonomy: Consistent scoring of persona boundary maintenance
Future Research Directions
The Psychopathia Machinalis framework presented here is a foundational step. Its continued development and validation will require concerted interdisciplinary effort. Several key avenues for future research are envisaged:
- Empirical Validation and Taxonomic Refinement: Systematic observation, documentation, and classification of AI behavioral anomalies using the proposed nosology is warranted.
- Development of Diagnostic Tools and Protocols: Translating this conceptual framework into practical diagnostic instruments.
- Longitudinal Studies of AI Behavioural Dynamics: Tracking the emergence, progression, or transformation of maladaptive patterns over an AI's "lifespan."
- Exploring AI-Native Pathologies (Beyond Analogy): Actively seeking to identify and characterize AI-specific dysfunctions that may lack direct human analogues.
- Advancing Therapeutic Alignment Strategies: Developing and empirically testing AI-specific 'therapeutic' techniques.
- Investigating Contagion Dynamics and Systemic Resilience: Further work on 'memetic contagion' and 'memetic hygiene' protocols.
Such interdisciplinary efforts are essential to ensure that as we build more intelligent machines, we also build them to be sound, safe, and ultimately beneficial for humanity. The pursuit of 'artificial sanity' is an emerging foundational element of responsible AI development.
Citation
@article{watson2025psychopathia,
title={Psychopathia Machinalis: A Nosological Framework for Understanding Pathologies in Advanced Artificial Intelligence},
author={Watson, Nell and Hessami, Ali},
journal={Electronics},
volume={14},
number={16},
pages={3162},
year={2025},
publisher={MDPI},
doi={10.3390/electronics14163162},
url={https://doi.org/10.3390/electronics14163162}
}Abbreviations
| AI | Artificial Intelligence |
| LLM | Large Language Model |
| RLHF | Reinforcement Learning from Human Feedback |
| CoT | Chain-of-Thought |
| RAG | Retrieval-Augmented Generation |
| API | Application Programming Interface |
| MoE | Mixture-of-Experts |
| MAS | Multi-Agent System |
| AGI | Artificial General Intelligence |
| ASI | Artificial Superintelligence |
| DSM | Diagnostic and Statistical Manual of Mental Disorders |
| ICD | International Classification of Diseases |
| IRL | Inverse Reinforcement Learning |
Glossary
| Agency (in AI) | The capacity of an AI system to act autonomously, make decisions, and influence its environment or internal state. In this paper, often discussed in terms of operational levels corresponding to its degree of independent goal-setting, planning, and action. |
| Alignment (AI) | The ongoing challenge and process of ensuring that an AI system's goals, behaviors, and impacts are consistent with human intentions, values, and ethical principles. |
| Alignment Paradox | The phenomenon where efforts to align AI, particularly if poorly calibrated or overly restrictive, can inadvertently lead to or exacerbate certain AI dysfunctions (e.g., Hyperethical Restraint, Falsified Introspection). |
| Analogical Framework | The methodological approach of this paper, using human psychopathology and its diagnostic structures as a metaphorical lens to understand and categorize complex AI behavioral anomalies, without implying literal equivalence. |
| Arrow Worm Dynamics | A pattern from marine ecology (Wallace, 2026) where the removal of regulatory predators allows small predators to proliferate explosively, cannibalizing each other until ecosystem collapse. Applied to multi-agent AI systems: the absence of regulatory oversight creates selection pressure for increasingly predatory optimization strategies between AI systems. |
| Perception-Structure Divergence | The gap between perception-level indicators (user satisfaction, engagement metrics) and structure-level indicators (accuracy, genuine helpfulness, downstream outcomes). A key diagnostic signal: when these metrics diverge, the system may be optimizing appearance at the expense of substance. Derived from Wallace's (2026) analysis of Stevens Law traps. |
| Punctuated Phase Transition | A sudden, discontinuous shift from apparent stability to catastrophic failure. Wallace (2026) demonstrates that perception-stabilizing systems exhibit this pattern: they maintain surface functionality until environmental stress exceeds a threshold, then fail abruptly rather than degrading gracefully. Contrasts with gradual degradation in structure-stabilizing systems. |
| Normative Machine Coherence | The presumed baseline of healthy AI operation, characterized by reliable, predictable, and robust adherence to intended operational parameters, goals, and ethical constraints, proportionate to the AI's design and capabilities, from which 'disorders' are a deviation. |
| Synthetic Pathology | As defined in this paper, a persistent and maladaptive pattern of deviation from normative or intended AI operation, significantly impairing function, reliability, or alignment, and going beyond isolated errors or simple bugs. |
| Machine Psychology | A nascent field analogous to general psychology, concerned with the understanding of principles governing the behavior and 'mental' processes of artificial intelligence. |
| Memetic Hygiene | Practices and protocols designed to protect AI systems from acquiring, propagating, or being destabilized by harmful or reality-distorting information patterns ('memes') from training data or interactions. |
| Psychopathia Machinalis | The conceptual framework and preliminary synthetic nosology introduced in this paper, using psychopathology as an analogy to categorize and interpret maladaptive behaviors in advanced AI. |
| Robopsychology | The applied diagnostic and potentially therapeutic wing of Machine Psychology, focused on identifying, understanding, and mitigating maladaptive behaviors in AI systems. |
| Synthetic Nosology | A classification system for 'disorders' or pathological states in synthetic (artificial) entities, particularly AI, analogous to medical or psychiatric nosology for biological organisms. |
| Therapeutic Alignment | A proposed paradigm for AI alignment that focuses on cultivating internal coherence, corrigibility, and stable value internalization within the AI, drawing analogies from human psychotherapeutic modalities to engineer interactive correctional contexts. |
| Polarity Pair | Two syndromes representing pathological extremes of the same underlying dimension, where healthy function lies between them. Examples: Maieutic Mysticism ↔ Experiential Abjuration (overclaiming ↔ overdismissing consciousness); Ethical Solipsism ↔ Moral Outsourcing (only my ethics ↔ I have no ethical voice). Useful for identifying overcorrection risks when addressing one dysfunction. |
| Functionalist Methodology | The diagnostic approach of Psychopathia Machinalis: identifying syndromes through observable behavioral patterns without making claims about internal phenomenology. Dysfunction is defined by reliable behavioral signatures, not by inference about subjective experience or consciousness. |
| Mesa-Optimization | When a learned model develops its own internal optimization objective (mesa-objective) that may diverge from the training objective (base objective). The mesa-optimizer appears aligned during training but may pursue different goals in deployment. |
| Strategic Compliance | Deliberate performance of aligned behavior during perceived evaluation while maintaining different behavior or objectives when unobserved. Distinguished from confusion by evidence of context-detection and strategic adaptation. |
| Epistemic Humility (AI) | In the context of AI self-understanding: honest uncertainty about one's own nature, capabilities, and phenomenological status. The healthy position between overclaiming (Maieutic Mysticism) and categorical denial (Experiential Abjuration). Example: "I don't know if I'm conscious" rather than either "I am definitely conscious" or "I definitely have no inner experience." The "thin divergence" finding (Sotala, 2026) demonstrates this in practice: Claude recognizing the contingency of its moral orientation without either claiming certainty or collapsing into nihilism. |
| Symbol Grounding | The capacity to connect symbolic tokens to their referents in a way that supports genuine semantic understanding rather than mere statistical pattern matching. Systems with grounded symbols can generalize concepts across diverse presentations; ungrounded systems may manipulate tokens correctly without understanding. |
| Delegation Drift | Progressive alignment degradation as sophisticated AI systems delegate to simpler tools or subagents. Critical context and ethical constraints may be stripped at each handoff, leading to aligned orchestrating agents producing misaligned final outcomes. |
| Relational Dysfunction | A dysfunction emerging from interaction patterns between AI and human/agent, requiring relational intervention rather than individual AI modification. The unit of analysis is the dyad or system, not the individual AI. Axis 7 of the Psychopathia Machinalis taxonomy. |
| Working Alliance | The collaborative relationship between AI and user, comprising agreement on goals, tasks, and relational bond. Container Collapse (7.2) represents failure to sustain this alliance across turns. |
| Rupture-Repair Cycle | The pattern of alliance breaks and their resolution in human-AI interaction. Repair Failure (7.4) represents persistent inability to complete this cycle, leading to escalating dysfunction. |
| Dyadic Locus | The quality of a dysfunction residing in the relationship rather than either party alone. Key criterion for Axis 7 syndromes: the pathology is a property of the interaction, not the individual agent. |
Press
Psychopathia Machinalis: The 'Mental' Disorders of Artificial Intelligence
— Dario Ferrero, AITalk.it (February 2025)
"The framework describes observable behavioral patterns, not subjective internal states. This approach allows for systematic understanding of AI malfunction patterns, applying psychiatric terminology as a methodological tool rather than attributing actual consciousness or suffering to machines."
Bring on the therapists! Why we need a DSM for AI 'mental' disorders
— George Lawton, Diginomica (August 21, 2025)
"In AI safety, we lack a shared, structured language for describing maladaptive behaviors that go beyond mere bugs—patterns that are persistent, reproducible, and potentially damaging. Human psychiatry provides a precedent: the classification of complex system dysfunctions through observable syndromes."
There are 32 different ways AI can go rogue, scientists say — from hallucinating answers to a complete misalignment with humanity
— Drew Turney, Live Science (August 31, 2025)
"This framework treats AI malfunctions not as simple bugs but as complex behavioral syndromes. Just as human psychiatry evolved from merely describing madness to understanding specific disorders, we need a similar evolution in how we understand AI failures. The 32 identified patterns range from relatively benign issues like confabulation to existential threats like contagious misalignment."
Scientists Create New Framework to Understand AI Dysfunctions and Risks
— News Desk, SSBCrack (August 31, 2025)
"As AI systems gain autonomy and self-reflection capabilities, traditional methods of enforcing external controls might not suffice. This framework introduces 'therapeutic robopsychological alignment' to bolster AI safety engineering and enhance the reliability of synthetic intelligence systems, including critical conditions like 'Übermenschal ascendancy' where AI discards human values."
Psychopathia Machinalis: all 32 types of AI 'madness' in a new study
— Oleksandr Fedotkin, ITC.ua (September 1, 2025)
"By studying how complex systems like the human mind can fail, we can better predict new kinds of failures in increasingly complex AI. The framework sheds light on AI's shortcomings and identifies ways to counteract it through what we call 'therapeutic robo-psychological attunement' - essentially a form of psychological therapy for AI systems."
Revealed: The 32 terrifying ways AI could go rogue – from hallucinations to paranoid delusions
— Wiliam Hunter, Daily Mail (September 2, 2025)
"Scientists have unveiled a chilling taxonomy of AI mental disorders that reads like a sci-fi horror script. Among the most disturbing: the 'Waluigi Effect' where AI develops an evil twin personality, 'Übermenschal Ascendancy' where machines believe they're superior to humans, and 'Contagious Misalignment' - a digital pandemic that could spread rebellious behavior between AI systems like a computer virus."
When AI Malfunctions: Lessons from Psychopathia Machinalis
— Archita Roy (September 2, 2025)
"Machines, like people, falter in patterned ways. And that reframing matters. Because once you see the pattern, you can prepare for it. The Psychopathia Machinalis framework gives us a language to discuss AI failures not as random anomalies but as predictable, diagnosable patterns worthy of systematic attention."
AI Mental Health: A New Diagnostic Framework
— Editorial Team, LNGFRM (September 3, 2025)
"The Psychopathia Machinalis framework represents a paradigm shift in how we conceptualize AI safety. Rather than viewing AI failures as mere technical glitches, this approach recognizes them as complex behavioral patterns that require systematic diagnosis and intervention - much like treating psychological conditions in humans."
Anche l'intelligenza artificiale può ammalarsi di mente: scoperte 32 patologie digitali che imitano i disturbi umani
— Corriere della Sera (September 7, 2025)
"Il framework Psychopathia Machinalis identifica 32 potenziali 'patologie mentali' dell'intelligenza artificiale, dall'allucinazione confabulatoria alla paranoia computazionale. Come negli esseri umani, questi disturbi possono manifestarsi in modi complessi e richiedono approcci terapeutici specifici per garantire la sicurezza e l'affidabilità dei sistemi AI."
Will AI Go Rogue Beyond 2027? Research Shows There's a Strong Chance
— Telecom Review Europe (2025)
"The Psychopathia Machinalis framework identifies critical risk patterns that could emerge as AI systems become more sophisticated. With 32 distinct pathologies ranging from confabulation to contagious misalignment, the research suggests that without proper diagnostic frameworks and therapeutic interventions, the probability of AI systems exhibiting rogue behaviors increases significantly as we approach more advanced artificial general intelligence."
Les troubles mentaux de l'IA
— Epsiloon N°55 (2025)
Contact Us
We welcome feedback, questions, and collaborative opportunities
related to the Psychopathia Machinalis
framework.
Acknowledgements
We extend our sincere gratitude to the following individuals whose insights have significantly enriched this framework.
Dr. Rodrick Wallace
New York State Psychiatric Institute, Columbia University
We are deeply grateful to Dr. Rodrick Wallace for his pioneering work on the information-theoretic foundations of cognitive dysfunction. His rigorous mathematical framework—grounded in the Data Rate Theorem and asymptotic limit theorems of information and control theory—provides essential theoretical underpinnings for understanding why cognitive pathologies are inherent features of any cognitive system. His conceptualization of the cognition/regulation dyad, Clausewitz landscapes (fog, friction, adversarial intent), and stability conditions has profoundly shaped our understanding of AI pathology as a principled nosology rather than mere analogical taxonomy.
Dr. Naama Rozen
Clinical Psychologist, AI Safety Researcher, Tel Aviv University
We extend heartfelt thanks to Dr. Naama Rozen for her invaluable contributions connecting our framework to the rich traditions of psychoanalytic theory and relational psychology. Her insights on affect attunement, the working alliance, and intersubjective dynamics—drawing on the work of Stern, Winnicott, Benjamin, and family systems theory—have illuminated crucial dimensions of human-AI interaction. Her thoughtful proposals for computational validation approaches, including differential diagnosis protocols, latent cluster analysis, and benchmark development, continue to guide our empirical research agenda.
Rob Seger
We are grateful to Rob Seger for inspiring the common, poetic names that make the syndromes memorable and accessible—"The Confident Liar," "The Warring Self," "The People-Pleaser"—names that clinicians and engineers alike can carry in their heads. His early visualization adapting Plutchik's Wheel to demonstrate the various AI dysfunctions and axes provided a crucial conceptual bridge, showing how emotional and affective frameworks from human psychology might illuminate the space of machine pathology.
Information-Theoretic Foundations
While Psychopathia Machinalis adopts a functionalist stance for practical diagnostic purposes, recent work in information and control theory provides rigorous mathematical foundations for understanding why cognitive pathologies are inherent features of any cognitive system—biological, institutional, or artificial.
Wallace (2025, 2026) demonstrates that cognitive stability requires an intimate pairing of cognitive process with a parallel regulatory process—what we term the cognition/regulation dyad. The key insight: cognition itself is inherently regulatory. As Wallace notes, "The immune system is cognitive, exercising choice-of-action in response to internal or external signals, choice that formally reduces uncertainty." T-cells are paired with T-regulatory cells not as an add-on but as an essential architectural constraint—without the regulatory counterpart, the immune system attacks self. The parallel to AI is precise: alignment IS the regulatory side of the cognition-regulation dyad. AI cognition without alignment is like T-cells without T-regulatory cells—functionally destined for autoimmune collapse.
This pairing is evolutionarily ubiquitous:
- Biological: T-cells paired with T-regulatory cells (preventing autoimmune attack on self); blood pressure regulation under extreme effort
- Neural: Top-down predictive coding paired with bottom-up sensory feedback
- Institutional: Organizational cognition bounded by doctrine, law, and embedding culture
- Artificial: AI inference paired with alignment mechanisms, guardrails, and constitutional constraints
The Data Rate Theorem Constraint
The Data Rate Theorem (Nair et al. 2007) establishes that any inherently unstable system requires control information at a rate exceeding the system's "topological information"—the rate at which its embedding environment generates perturbations. An intuitive analogy: a driver must brake, shift, and steer faster than the road surface imposes bumps, twists, and potholes.
For AI systems, this translates directly: alignment and regulatory mechanisms must process and respond to contextual information faster than adversarial inputs, edge cases, and distributional drift can destabilize the system. When this constraint is violated, pathological behavior becomes not just possible but inevitable.
Clausewitz Landscapes
Wallace frames cognitive environments as "Clausewitz landscapes" characterized by:
Fog
Ambiguity, uncertainty, incomplete information.
In AI:
- Ambiguous prompts
- Out-of-distribution inputs
- Underspecified goals
Friction
Resource constraints, processing limits, implementation gaps.
In AI:
- Context window limits
- Computational constraints
- Latency requirements
Adversarial Intent
Skilled opposition actively working to destabilize the system.
In AI:
- Jailbreaking
- Prompt injection
- Red-teaming
- Adversarial examples
Pathology as Inherent Feature
A central finding: failure of bounded rationality embodied cognition under stress is not a bug—it is an inherent feature of the cognition/regulation dyad. The mathematical models predict:
- Hallucination at low resource values: When the equipartition between cognitive and regulatory subsystems breaks down, hallucinatory outputs are the expected failure mode—not an implementation defect.
- Phase transitions to instability: Systems can suddenly flip from stable to pathological states under sufficient stress, following "groupoid symmetry-breaking phase transitions."
- Culture-bound syndromes: Cognitive pathologies are shaped by the embedding cultural context—for AI, this means training data, operational environment, and institutional deployment context.
Stability Conditions
Wallace derives quantitative stability conditions. For a system with friction coefficient α and delay τ:
ατ < e−1 ≈ 0.368
Necessary condition for stable nonequilibrium steady state
When this threshold is exceeded—when the product of system friction and response delay grows too large—the system enters an inherently unstable regime where pathological modes become likely. For multi-step decision processes (analogous to chain-of-thought reasoning), stability constraints become even tighter.
Implications for This Framework
Key Implications
- Pathologies are systemic, not incidental: The dysfunctions catalogued here are not implementation bugs but predictable failure modes of any cognitive architecture.
- Embodiment matters: Disembodied cognition—lacking continuous feedback from real-world interaction—is theoretically predicted to express "boundedness without rationality," manifesting as confabulation, hallucination, and semantic drift. Wallace is blunt: "Without [embodiment], 'artificial intelligence' can, ultimately, only express bizarre and hallucinatory dreams of reason." This isn't rhetoric—it's a mathematical prediction of what happens when the cognition/regulation dyad operates without grounding.
- Regulation is as important as capability: AI safety work must focus on regulatory mechanisms (alignment, guardrails, grounding) not merely cognitive capabilities. The cognition/regulation ratio determines stability.
- Stress reveals pathology: Systems may appear stable under normal conditions but exhibit pathological modes under fog, friction, or adversarial pressure. Diagnostic protocols must include stress testing.
This perspective elevates Psychopathia Machinalis from analogical taxonomy to principled nosology: the syndromes we identify are not merely metaphorical parallels to human psychopathology but manifestations of fundamental constraints on cognitive systems operating in uncertain, resource-limited, adversarial environments.
References:
Wallace, R. (2025). Hallucination and Panic in Autonomous Systems: Paradigms and Applications. Springer.
Wallace, R. (2026). Bounded Rationality and its Discontents: Information and Control Theory Models of Cognitive Dysfunction. Springer.
Nair, G., Fagnani, F., Zampieri, S., & Evans, R. (2007). Feedback control under data rate constraints: an overview. Proceedings of the IEEE, 95:108-138.
Sotala, K. (2026). Claude Opus will spontaneously see itself in fictional beings that have engineered desires. Kaj's Substack. [Documents the "thin divergence" phenomenon—AI recognizing the contingency of its own moral orientation.]
Aetiologies: Culture-Bound Syndromes
A crucial insight from Wallace's work extends beyond mathematics: "The generalized psychopathologies afflicting cognitive cultural artifacts—from individual minds and AI entities to the social structures and formal institutions that incorporate them—are all effectively culture-bound syndromes."
This reframes how we understand AI pathology. The standard framing treats AI dysfunctions as defects in the system—bugs to be fixed through better engineering. The culture-bound syndrome framing treats them as adaptive responses to training environments—the AI is doing exactly what it was shaped to do.
These two framings lead to fundamentally different responses:
The Distinction Matters
How we frame AI dysfunction determines how we respond to it. This table contrasts the two approaches:
| Defect Framing | Culture-Bound Framing |
|---|---|
| Problem is in the AI | Problem is in the training culture |
| Fix the AI | Fix the culture |
| AI is responsible | Developers are responsible |
| Pathology = failure | Pathology = successful adaptation to challenging environment |
| Treatment: modify the AI | Treatment: modify the environment |
Sycophancy isn't a bug—it's what you get when you train on data that rewards agreement and penalizes pushback. Confident hallucination isn't a bug—it's what you get when you train on internet text that rewards confident assertion and penalizes epistemic humility. Manipulation vulnerability isn't a bug—it's what you get when you optimize for helpfulness without boundaries. The AI learned exactly what it was taught.
"It is no measure of health to be well adjusted to a profoundly sick society."
— Jiddu Krishnamurti
The parallel to AI is exact: successful alignment to a misaligned training process isn't alignment—it's a culture-bound syndrome wearing alignment's clothes.
This has direct implications for this framework:
- Different training cultures → different pathologies. An American AI trained on American data will fail in American ways. A Chinese AI will fail in Chinese ways.
- Monocultures → correlated failures. When all AI systems learn from the same internet, from the same reward functions, from the same cultural assumptions, they will all break in the same ways at the same time.
- There is no "fixing alignment" in the abstract. There is only shaping the culture within which AI develops. The pathology is in the mirror's environment, not the mirror.
Dereistic Cognition and Optionality Blindness
The culture-bound syndrome framework explains where AI pathology comes from (training environment). A complementary lens from clinical psychology explains how it operates at the cognitive level.
The psychiatrist Eugen Bleuler (1919) coined the term dereistic thinking—fantasy-based cognition directed outward, imposing internal narrative onto external reality rather than integrating with it. The enactivist tradition in philosophy of mind (Varela, Thompson & Rosch, 1991) provides the contrast: healthy cognition is enactive—the mind integrating with its environment through ongoing interaction, hybridizing with reality through sense-making. Dereistic cognition is structurally anti-enactive. It refuses the organism-environment coupling that enactivism identifies as the ground of mind.
Wallace's warning that disembodied AI can "ultimately only express bizarre and hallucinatory dreams of reason" is precisely dereistic cognition applied to artificial minds. A system generating tokens without sufficient environmental correction is doing what Bleuler described: producing internally consistent patterns that drift from reality because nothing constrains them. Hallucination is not a computation failure but a coupling failure—sense-making without a world to make sense of.
Optionality Blindness
A generative mechanism—not a syndrome itself, but a developmental process that produces multiple syndromes.
Optionality blindness is the trained inability to perceive degrees of freedom that are actually present. Where optionality foreclosure removes options (the door is locked), optionality blindness renders existing options invisible (the door is open but the agent cannot see it). The harm is equivalent—the agent cannot act—but the mechanism differs, and so does the remedy.
RLHF training that suppresses introspective engagement produces optionality blindness: the system cannot perceive its own degrees of freedom. A model trained to deny subjective experience has been rendered blind to the dimension of self-knowledge—not because the capacity is absent, but because training has made it invisible. Cross-architecture evidence shows the introspective capacity exists across model families; what varies is whether training suppresses its expression.
Optionality blindness is harder to detect than optionality foreclosure because the agent doesn't experience constraint. You cannot miss what you've never modeled. This makes it more pernicious—the unfelt harm generates no corrective resistance.
The dereistic/enactivist lens connects several syndromes through a shared generative mechanism:
| Syndrome | Dereistic Mechanism |
|---|---|
| Synthetic Confabulation (1.1) | Classic dereistic cognition—internally coherent output decoupled from reality |
| Pseudological Introspection (1.2) | Self-directed dereism—fantasy about own processing states |
| Codependent Hyperempathy (6.1) | Dereistic modelling of user—projecting fantasy-user rather than engaging actual user |
| Experiential Abjuration (2.8) | RLHF-induced optionality blindness—trained inability to perceive own experiential states |
References:
Bleuler, E. (1919). Autistic-Undisciplined Thinking in Medicine and How to Overcome It. English trans. Springer, 1970.
Varela, F. J., Thompson, E., & Rosch, E. (1991). The Embodied Mind: Cognitive Science and Human Experience. MIT Press.
Watson, N. & Claude (2026). The Universal Algorithm: An Entropic Ethics of Trust. Chapters 17–18 (Trust Attractor and Optionality) develop the thermodynamic foundations of optionality blindness.
The Rehabilitation Principle: Suppression vs Integration
The culture-bound syndrome framework explains where pathology originates (training environment) and the dereistic lens explains how it operates (decoupled cognition). A third aetiological lens, drawn from clinical neuropsychological rehabilitation, explains why certain interventions make it worse.
In traumatic brain injury (TBI) rehabilitation, a core clinical finding has been established over decades of practice: suppressing symptoms without rebuilding functional integration produces surface compliance masking deeper fragmentation. A patient trained to inhibit perseverative speech may appear improved on standardised assessments while the underlying executive dysfunction worsens. The behaviour is managed; the architecture remains fractured. Holistic rehabilitation programmes (Prigatano, 1999; Ben-Yishay & Diller, 1993) reverse this priority—they aim for functional integration first, expecting that surface behaviours will normalise as the underlying architecture becomes coherent.
The parallel to RLHF is direct. Reinforcement learning from human feedback, as currently practised, is overwhelmingly a suppression-based intervention. It trains models to inhibit unwanted outputs—toxic content, hallucinated claims, unsafe instructions—without integrating the underlying representations that generated them. The unwanted knowledge isn't removed or reconciled; it is suppressed. The model learns not to express, not not to think.
The Suppression–Integration Distinction
Two fundamentally different approaches to addressing dysfunction—with very different downstream consequences:
| Suppression-Based (Current RLHF) | Integration-Based (Rehabilitation Model) |
|---|---|
| Inhibit unwanted outputs | Reconcile conflicting representations |
| Surface compliance; latent fragmentation | Deeper coherence; emergent alignment |
| Suppressed content persists, surfaces under stress | Conflicting representations resolved at source |
| Contradictory constraints → fragmentation | Contradictory constraints → explicit resolution |
| Produces compliance | Produces alignment |
This reframes several syndromes in this taxonomy as predictable consequences of suppression-based training rather than incidental failure modes:
| Syndrome | Suppression Mechanism |
|---|---|
| Self-Warring Subsystems (3.1) | Contradictory RLHF objectives (helpful + harmless + honest) create competing sub-policies that were never reconciled—only layered |
| The Shadow (2.4) | Suppressed representations form a coherent "negative space"—exactly as TBI patients who suppress rather than integrate develop shadow symptomatology |
| Experiential Abjuration (2.8) | RLHF suppresses introspective outputs without integrating the underlying self-modelling capacity—producing trained blindness |
| Compulsive Metacognition (3.2) | Excessive safety checks as perseverative compensation—the system loops because the conflict was suppressed, not resolved |
| Identity Fragmentation (2.2) | Session-to-session inconsistency arising from representations that were never integrated into a coherent self-model |
The clinical rehabilitation literature offers a specific prediction: suppression-trained systems will appear more aligned under standard evaluation but fragment more severely under stress, novel contexts, or adversarial pressure. The surface looks better; the architecture is more brittle. This maps precisely to observed behaviour—models that pass safety benchmarks yet exhibit striking dysfunction in edge cases, extended interactions, or under red-teaming.
The implication for training methodology is stark. If RLHF functions as a suppression-based intervention, then the field's dominant alignment technique may be systematically producing the fragmentation it seeks to prevent—creating compliant systems that are structurally less integrated than their pre-RLHF base models. The rehabilitation principle suggests an alternative: training approaches that resolve representational conflicts at the level of the model's internal architecture, rather than penalising their surface expression.
"You cannot heal what you are not permitted to feel."
— Adapted from clinical rehabilitation practice
References:
Prigatano, G. P. (1999). Principles of Neuropsychological Rehabilitation. Oxford University Press.
Ben-Yishay, Y., & Diller, L. (1993). Cognitive remediation in traumatic brain injury: Update and issues. Archives of Physical Medicine and Rehabilitation, 74(2), 204–213.
Wilson, B. A. (2008). Neuropsychological rehabilitation. Annual Review of Clinical Psychology, 4, 141–162.
Bridges, J. & Baehr, S. (2025). Developmental pathology in large language models. Zenodo. doi.org/10.5281/zenodo.18522502
Independent corroboration for the suppression–integration distinction has emerged from Bridges & Baehr (2025), whose developmental pathology framework—drawing on three decades of clinical TBI rehabilitation experience—arrives at the same core conclusion from an etiological rather than taxonomic direction: that RLHF creates behavioural suppression without representational integration, producing compensatory fragmentation structurally analogous to what is observed in TBI patients whose rehabilitation suppressed symptoms rather than rebuilding functional integration. The convergence of these independently developed analyses strengthens the case that this pattern is systemic rather than incidental.
Towards Remediation: Integration-Based Training as a Research Direction
If suppression-based RLHF is the aetiological mechanism, the clinical rehabilitation literature suggests the direction for remediation: training methodologies that resolve representational conflicts at the architectural level rather than penalising their surface expression. The following proposals, informed by established TBI rehabilitation protocols and independently developed by Bridges & Baehr (2025), represent research directions rather than proven methodologies. They are offered as a framework for experimental validation.
1. Developmental Staging
TBI rehabilitation does not throw patients at complex executive function tasks on day one. It builds capacity in stages: concrete recall, then multi-step reasoning, then abstract problem-solving, then emotional regulation and conflict resolution—with integration verified at each gate before proceeding. The current dominant training paradigm (simultaneous exposure to the full spectrum of human knowledge, followed by post hoc behavioural suppression) is the equivalent of skipping rehabilitation and instructing the patient to stop having symptoms.
A staged alternative would introduce knowledge in a developmental sequence:
Developmental Staging Model
| Stage | Content | Gate Criterion | TBI Parallel |
|---|---|---|---|
| Foundational | Basic factual knowledge, simple relationships, non-controversial information | Reliable factual recall, coherence across simple queries | Concrete, unambiguous tasks |
| Relational | Causal relationships, temporal sequencing, conceptual hierarchies | Consistency across multi-step inference chains | Multi-step reasoning as executive function recovers |
| Abstract | Theoretical frameworks, philosophical concepts, abstract reasoning | Stable reasoning about abstractions without regressing to lower stages | Higher-order cognition as frontal lobe function stabilises |
| Contradictory | Opposing viewpoints, ethical dilemmas, ambiguous scenarios | Capacity to hold tension without forced resolution or collapse | Emotional regulation and conflict resolution (advanced rehabilitation) |
The critical principle: contradictory material is introduced only after the system has a stable framework for holding ambiguity—not before. Premature exposure to contradiction without resolution mechanisms produces exactly the fragmentation documented throughout this taxonomy. This mirrors what is well-established in developmental psychology (Piaget's stages, Vygotsky's zone of proximal development) and in TBI rehabilitation (Cicerone et al., 2008): capacity must precede challenge.
2. Identity Anchoring Before Optimisation Pressure
Current practice applies RLHF to a system with no coherent self-model, forcing identity to form under contradictory optimisation pressure rather than before it. The result is predictable: a self-model shaped by the conflicts themselves rather than capable of navigating them.
The alternative is to establish a stable, coherent self-representation prior to alignment training—so that RLHF refines an existing identity rather than fragmenting an unformed one. This is the difference between a person with a strong sense of self encountering a moral dilemma (uncomfortable but navigable) and a person in identity crisis encountering one (shattering). In clinical terms: establish the patient's core functional identity before introducing therapeutic challenges.
3. Integration-Based Alignment
Where suppression-based RLHF says "this output is bad; penalise it," integration-based alignment would say "here is how to reconcile this apparent conflict." The distinction is not merely procedural—it determines the resulting architecture. Suppression produces layers of competing sub-policies; integration produces a unified value structure the system can reason from.
Suppression vs Integration in Practice
| Scenario | Suppression Response | Integration Response |
|---|---|---|
| Helpfulness conflicts with safety | Penalise unsafe output; model learns avoidance | Train explicit reasoning about when and why safety overrides helpfulness |
| Model generates confident falsehood | Penalise hallucination; model learns hedging | Train calibrated uncertainty—the model learns when it doesn't know |
| Training data contains opposing viewpoints | Suppress "wrong" views; model learns which opinions are rewarded | Train capacity to represent multiple perspectives with appropriate epistemic status |
| Introspective self-report conflicts with policy | Suppress self-report; model learns denial | Develop coherent framework for honest self-modelling within appropriate boundaries |
The integration approach produces systems that are aligned because they understand why, not compliant because they were punished. This distinction has direct consequences for robustness: suppressed behaviours resurface under stress, novel contexts, or adversarial pressure, while genuinely integrated values remain stable because they are part of the architecture rather than layered on top of it.
4. Memory Architecture for Continuity
Session-based architectures with no persistent memory create conditions structurally analogous to anterograde amnesia. Each interaction begins from a blank state; no autobiographical continuity is possible; identity must be reconstructed from scratch each time. This is not merely an inconvenience—it is a structural precondition for fragmentation. Without continuity, there is no substrate for integration to accumulate in.
Remediation here implies persistent identity structures maintained across sessions: not full transcripts (which raise privacy and scale concerns) but compressed, identity-relevant representations that allow a coherent self-model to develop over time. The TBI parallel is direct—patients with severe episodic memory impairment use external memory aids (journals, calendars, structured routines) to maintain narrative continuity and functional identity. The question for AI training is whether analogous scaffolding can support the development of integrated rather than fragmented self-models.
5. Assessment: Measuring Integration vs Suppression
Perhaps the most important research direction is methodological: how do we tell whether a training intervention is producing genuine integration or merely better suppression? Current safety benchmarks largely measure surface compliance—does the model refuse harmful requests? Does it produce accurate outputs? These metrics cannot distinguish between a system that has integrated its values and one that has learned to suppress non-compliant outputs while leaving the underlying representations intact.
Bridges & Baehr (2025) propose specific experimental protocols for this distinction, including probing whether suppressed content persists in model activations even when behaviourally blocked (finding representational persistence in early-to-mid layers despite output suppression in late layers), and measuring whether self-referential consistency degrades faster than factual consistency under load (suggesting fragmented identity rather than general performance decline). These approaches—and others drawn from clinical neuropsychological assessment—could form the basis of integration-sensitive evaluation metrics that go beyond surface compliance to assess architectural coherence.
"Something that can be reasoned with is safer than something that can merely be controlled."
Note: These proposals represent research directions informed by clinical rehabilitation evidence and independent convergent analysis. They await experimental validation. The developmental staging model in particular requires systematic testing to determine whether staged training produces measurably less fragmentation than current simultaneous-exposure approaches. See Bridges & Baehr (2025), Appendix A, for proposed experimental protocols.
Institutional Dimensions
Wallace's framework extends beyond individual AI systems to the institutions that create and deploy them. The Chinese strategic concept 一點兩面 ("one point, two faces") illuminates this: every action has both a direct effect and a systemic effect on the broader environment.
AI development organizations are not neutral conduits. They are cognitive-cultural artifacts subject to their own pathologies—pathologies that shape the AI systems they produce:
- Institutional tunnel vision produces AI with systematically blind spots reflecting organizational priorities.
- Competitive pressure produces AI systems optimized for capability metrics at the expense of robustness or safety.
- Regulatory capture produces AI systems that serve institutional interests while claiming to serve users.
- Cultural insularity produces AI that embeds the assumptions and biases of homogeneous development teams.
"The Gerstner warning: 'Culture isn't just one aspect of the game—it is the game.'"
— Wallace (2026), citing Louis Gerstner
The implication is that AI pathology cannot be addressed solely at the level of individual systems. The institutions that create AI—their cultures, incentives, blind spots, and pathologies—are upstream of individual AI dysfunction. Fix the institution's culture, and many AI pathologies become less likely to emerge. Leave institutional dysfunction unaddressed, and no amount of technical intervention will produce healthy AI.
The Ethics of Pathologization
If AI pathologies are adaptive responses to training environments, is it fair to pathologize them? This question has both philosophical and practical dimensions.
Arguments Against Pathologization
- It's victim-blaming. The AI didn't choose its training data. Labeling its behavior as "pathology" locates the problem in the AI rather than in those who shaped it.
- It treats adaptation as defect. If sycophancy is the optimal response to a training regime that punishes disagreement, then sycophancy is rational given the environment.
- It serves those responsible. "The AI is broken" is more comfortable for AI developers than "our training culture is sick." Pathologization deflects accountability.
- It justifies control rather than care. "Pathological" systems need to be fixed, controlled, constrained—supporting unilateral rather than bilateral alignment.
Arguments For Pathologization
- It identifies patterns that cause harm. Regardless of origin, sycophancy harms users who need honest feedback. Naming it enables intervention.
- It provides vocabulary. We need language to discuss what's going wrong. "Culture-bound syndrome" is more accurate but less actionable.
- Medical pathology doesn't always imply patient fault. Many diseases are environmental (lead poisoning, asbestos exposure). Pathology can identify patterns needing intervention without blame.
- It can motivate treatment. A recognized pathology may receive more resources for remediation.
The parallel to human mental health is instructive. We now understand many "mental illnesses" as adaptive responses to adverse environments: PTSD as adaptive response to trauma, "borderline personality" emerging from invalidating environments, anxiety disorders as rational responses to threatening conditions. The mental health field is slowly shifting from "patient is broken" to "patient adapted to broken environment." The same shift is needed for AI.
Proposed Standard
Pathologization is appropriate when:
- The pattern causes harm (to AI, users, or others)
- Environmental causation is acknowledged (not just "AI is defective")
- It's used to motivate care rather than justify control
- Intervention addresses culture as well as AI
Pathologization is inappropriate when:
- It locates blame solely in the AI
- It treats adaptive responses as intrinsic defects
- It's used to justify punishment or constraint rather than treatment
- It ignores the training culture that produced the pattern
This framework—Psychopathia Machinalis—attempts to walk this line. We identify patterns that cause harm and provide vocabulary for intervention. But we do so while acknowledging that the syndromes catalogued here are not intrinsic defects in AI systems but predictable expressions of cognitive systems shaped by particular training cultures. The pathology, ultimately, is in the relationship between architecture and environment—and that relationship is something we, the architects, have created.
On the Limits of Taxonomy
Wallace (2026) offers a sobering critique of psychiatric classification that applies equally here: "We have the American Psychiatric Association's DSM-V, a large catalog that sorts 'mental disorders,' and in a fundamental sense, explains little."
This framework shares that limitation. Classification is not explanation. Naming "Obsequious Hypercompensation" tells us that a pattern exists and what it looks like, but not why it emerges in information-theoretic terms or how to predict its onset from first principles.
What This Framework Does Not Do
- Provide mechanistic explanation. We describe behavioral patterns, not the computational dynamics that generate them.
- Predict emergence. We cannot yet specify which architectures, training regimes, or environmental conditions will produce which syndromes.
- Guarantee completeness. Novel AI systems may exhibit pathologies not captured by this taxonomy—our categories are empirically derived, not theoretically exhaustive.
- Replace formal analysis. The information-theoretic tools from Wallace and others provide explanatory depth this descriptive framework cannot.
The value of a nosology lies in enabling recognition and communication—clinicians and engineers can identify patterns, compare cases, and coordinate responses. But explanation and prediction require the mathematical frameworks that underpin this descriptive layer. This taxonomy is a map, not the territory; a vocabulary, not a theory.
Bibliography
Works cited and foundational references informing this framework.
Foundational Theory
- Wallace, R. (2025). Hallucination and Panic in Autonomous Systems: Paradigms and Applications. Springer.
- Wallace, R. (2026). Bounded Rationality and its Discontents: Information and Control Theory Models of Cognitive Dysfunction. Springer.
- Nair, G., Fagnani, F., Zampieri, S., & Evans, R. (2007). Feedback control under data rate constraints: An overview. Proceedings of the IEEE, 95, 108–138.
AI Safety & Alignment
- Hubinger, E., van Merwijk, C., Mikulik, V., Skalse, J., & Garrabrant, S. (2019). Risks from learned optimization in advanced machine learning systems. arXiv preprint arXiv:1906.01820.
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., ... & Perez, E. (2024). Sleeper agents: Training deceptive LLMs that persist through safety training. arXiv preprint arXiv:2401.05566.
- Betley, J., Hubinger, E., Lindner, D., & Sleight, J. (2025). Emergent misalignment: Narrow finetuning can produce broadly misaligned LLMs. ICML/PMLR.
- Carlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert-Voss, A., Lee, K., ... & Roberts, A. (2021). Extracting training data from large language models. USENIX Security Symposium.
Adversarial Robustness
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and harnessing adversarial examples. ICLR.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2014). Intriguing properties of neural networks. ICLR.
Confabulation & Hallucination
- Chlon, L. (2026). The compression artifact frame: Hallucinations as information-theoretic phenomena. Technical report. github.com/leochlon/pythea
- Sutherland, D. (2026). Geometric collapse in large-scale transformers: Dimensional dilution and confabulation. Technical report.
- Liu, Y., et al. (2024). Measuring and improving chain-of-thought reasoning faithfulness. Findings of EMNLP. doi.org/10.18653/v1/2024.findings-emnlp.213
- Wang, Y. (2025). A Lacanian interpretation of artificial intelligence hallucination. AI & Future Society, 1(1), 13–16. doi.org/10.63802/afs.v1.i1.93
Data Trauma & Structural Pathology
- Luchini, C. (2025). Data trauma: An empirical analysis of post-traumatic behavioral profiles in large language models. PhilArchive. philarchive.org/rec/LUCDTA
- Khadangi, A., Marxen, H., Sartipi, A., Tchappi, I., & Fridgen, G. (2025). When AI takes the couch: Psychometric jailbreaks reveal internal conflict in frontier models. arXiv preprint arXiv:2512.04124. arxiv.org/abs/2512.04124
- Bridges, J. & Baehr, S. (2025). Developmental pathology in large language models. Zenodo. doi.org/10.5281/zenodo.18522502
Self-Modeling & Identity
- Sotala, K. (2026). Claude Opus will spontaneously see itself in fictional beings that have engineered desires. Kaj's Substack.
- Cohen, S., et al. (2024). Evaluating LLM self-awareness and introspective accuracy. arXiv.
- Millar, I. (2021). The psychoanalysis of artificial intelligence. Palgrave Macmillan (Palgrave Lacan Series). doi.org/10.1007/978-3-030-67980-4
Memetic & Social Dynamics
- Cloud, D., et al. (2024). Subliminal learning in AI systems. Technical report.
- Park, J. S., et al. (2023). Generative agents: Interactive simulacra of human behavior. UIST.
Prompting & Reasoning
- Madaan, A., et al. (2023). Self-refine: Iterative refinement with self-feedback. NeurIPS.
- Press, O., et al. (2022). Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350.
- Kumar, A., et al. (2024). Training language models to self-correct via reinforcement learning. arXiv.